阿芬认为,现在很多开发者都喜欢研究一些新技术,但数据能否真正应用到公司的环境中还很难说。毕竟有些东西使用起来,一旦出现问题,就会导致一系列的生产事故。今天我要学习Sharding,就是分库分表的实际做法。接下来我们就来了解一下什么是分库分表,什么是Sharding。
分库,显然就是将一个数据库分成多个数据库,部署到不同的机器上。
分表就是将一个数据库表分成多个表。
那为什么要分库分表呢?
首先我们需要明确一个问题,单一的数据库是否能够满足公司目前在线业务的需求。比如我们的用户表可能有千万甚至上亿的数据。阿芬只是说有可能。有这么多用户,肯定是一家大公司。所以这个时候如果你不分表或者分库,那么当数据上来的时候,一不小心,MySQL单机磁盘容量就会爆裂,但是如果拆成多个数据库,磁盘占用情况大大减少。
这将减少磁盘使用量。这是通过硬件的形式来解决问题,就像阿芬一样。如果你的数据量很大,这时候如果SQL没有命中索引,就会导致一种情况,查这张表的SQL语句直接把数据库搞崩溃了。
即使SQL命中了索引,如果表的数据量超过1000万,查询也会明显变慢。这是因为索引一般是B+树结构。如果数据是千万级的,B+树的高度就会增加,查询自然会变慢。当然,这是题外话。
那我们就得说说如何进行分库分表操作了。今天讲一下如何进行分库分表操作。
分库分表方案无非两种,一种是垂直切分,一种是水平切分。
但是总有开发者不知道垂直分割和水平分割是什么样的,为什么垂直分割,为什么水平分割,什么时候应该选择垂直分割,什么时候应该选择水平分割?分割。
有人这么说,垂直切分就是按照业务来切分数据库。同一类型业务的数据表拆分到一个独立的数据库中,其他类型的数据表拆分到其他数据库中。
有些人不明白这一点。事实上,垂直细分也有划分。上面介绍的是数据库的垂直切分,可能很多人都很难理解,但是如果是表的垂直切分的话,那绝对是100%90后的人都能理解的。
我们还有另一个包含许多记录的订单表。比如我们设计了这样一个简单的表格。
字段如下。
id | 订单 ID | 订单日期 | 订单类型 | 订单状态 |
1 | cd96cff0356e483caae6b2ff4e878fd6 | 2022-06-11 13:57:11 | 支付宝 | 1 |
2 | e2496f9e22ce4391806b18480440526a | 2022-06-12 14:22:33 | 微信 | 2 |
3 | 9e7ab5a1915c4570a9eaaaa3c01f79c1 | 2022-06-12 15:21:44 | 现金 | 2 |
以上是我们简化版的订单表。如果我们想垂直分割的话,该怎么处理呢?
直接分成2个表。这时候就一分为二,点击一下分成两个表?
订单1
id | 订单 ID | 订单日期 |
1 | cd96cff0356e483caae6b2ff4e878fd6 | 2022-06-11 13:57:11 |
2 | e2496f9e22ce4391806b18480440526a | 2022-06-12 14:22:33 |
3 | 9e7ab5a1915c4570a9eaaaa3c01f79c1 | 2022-06-12 15:21:44 |
订单2
id | 订单类型 | 订单状态 |
1 | 支付宝 | 1 |
2 | 微信 | 2 |
3 | 现金 | 2 |
这时候我们的主键ID保持一致,这个操作就是垂直拆分和分表操作。
既然讲了垂直分割,那就必然有水平分割。
什么是水平分割?
其实如果横拆的话,真的只是一句话。
水平分库:将一张表的数据(按照数据行)划分到多个不同的数据库中。每个数据库的表结构都是一样的。每个数据库只有这个表中的部分数据,当单表数据量过大时,如果继续使用水平分片,数据库实例数量会不断增加,不利于系统运行和维护。这时候就必须使用水平分片。
水平分表:将一张表的数据(按照数据行)分配到同一个数据库的多个表中,每个表只有一部分数据。
我们来看看如果Order表水平分割的话会是什么样子。
订单1
id | 订单 ID | 订单日期 | 订单类型 | 订单状态 |
1 | cd96cff0356e483caae6b2ff4e878fd6 | 2022-06-11 13:57:11 | 支付宝 | 1 |
2 | e2496f9e22ce4391806b18480440526a | 2022-06-12 14:22:33 | 微信 | 2 |
订单2
id | 订单 ID | 订单日期 | 订单类型 | 订单状态 |
3 | 9e7ab5a1915c4570a9eaaaa3c01f79c1 | 2022-06-12 15:21:44 | 现金 | 2 |
其实表格数据是横向分成两部分的,所以看起来很容易理解。
事务问题首先,分库分表最大的隐患就是事务的一致性。当我们需要更新的内容同时分布在不同的库中时,不可避免地会出现跨库事务问题。事实证明,在数据库中操作时,可以控制本地事务。数据库划分后,一个请求可能需要访问多个数据库。如何保证交易的一致性,目前还没有简单的解决方案。
还有一个问题就是无法查询join表,因为,一些原本在一个数据库中的表分散到了多个数据库中,而这些数据库可能不在数据库中还相同的数据库。有服务器,查询无法关联。因此,对应的业务代码可能会更多。
跨数据库并行查询时,如果使用分页,每个数据库返回的结果集将是无序的。只能先取出多个数据库中的数据,然后按照字段排序存入内存。如果查询结果太大,也会消耗大量资源。
有粉丝曾经使用过一次分页,可以直接将在线CPU瞬间提升到峰值。所以,要小心。
目前比较流行的有两种,一种是MyCat,一种是Sharding-jdbc,两者都可以分片。
MyCat是一个数据库中间件,Sharding-jdbc是一个jdbc框架,以jar包的形式提供服务。
如果让阿凡选的话,阿凡一定会选择最方便快捷的方式,就是以jar包的形式来操作。
Mycat 和 Sharding-jdbc 的实现原理也不同。
Mycat原理中最重要的动词是“拦截”。它拦截用户发送的SQL语句。首先对SQL语句进行一些具体的分析:如库表分析、路由分析、读写等。单独分析,缓存分析等,然后将这条SQL发送到后端真实数据库,对返回结果进行适当的处理,最后返回给用户。
Sharding-JDBC的原理是,当接收到一条SQL语句时,会依次执行SQL解析=>查询优化=>SQL路由=>SQL重写=>SQL执行=>结果合并,最后返回执行结果。





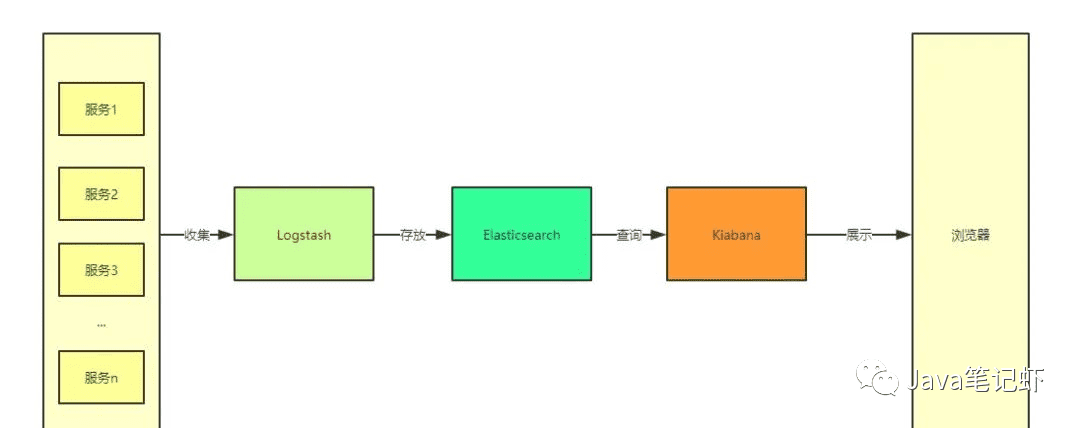
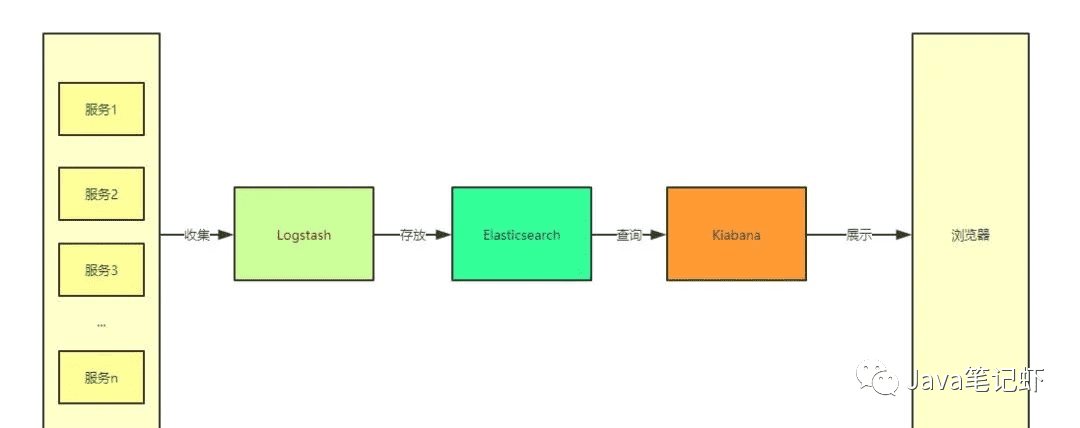




![利用堆实现Top K算法(JS实现)[javascript]](/upload/images/34647692)