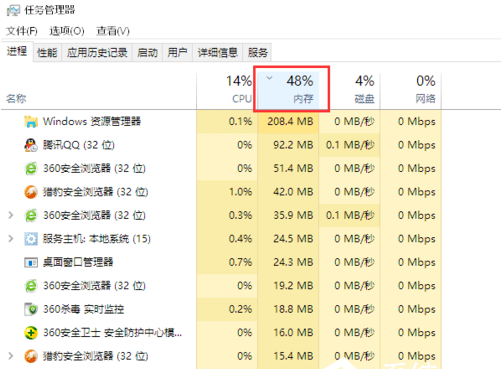
也就是说,它通过将键值映射到表中的某个位置来访问记录,以加快查找速度。这种映射函数称为哈希函数,存储记录的数组称为哈希表。
哈希表的方法其实很简单。就是通过固定的算法函数,即所谓的哈希函数,将Key转换为整数,然后将这个数调制到数组的长度。余数结果作为数组的下标,将值存储到以数字为下标的数组空间中。
使用哈希表查询时,再次使用哈希函数将key转换为对应的数组下标,定位空间获取value。这样就可以充分利用数组的定位。数据位置的性能。
问题分析:
要统计最热门的查询,首先统计每个查询出现的次数,然后根据统计结果找到前 10 个。所以我们可以根据这个思想分两步设计算法。
即这个问题的解决分为以下两步:
第一步:查询统计(统计每个Query出现的次数)
查询统计有以下两种方法可供选择:
1)、直接排序法(常在日志中时)在文件中计数,使用 cat file|format key|sort | uniq -c | sort -nr | head -n 10,就是这个方法)
首先我们首先想到的算法就是排序。首先,对这个日志中的所有查询进行排序,然后遍历排序后的查询,统计每个查询出现的次数。
但是题中有明确的要求,就是内存不能超过1G,并且有1000万条记录。每条记录为255Byte。显然,会占用2.375G内存。这个条件不符合要求。
让我们回忆一下数据结构课程中所学的内容。当数据量比较大,内存无法容纳时,我们可以使用外部排序来排序。这里我们可以使用归并排序,因为归并排序有更好的时间复杂度O(NlgN)。
排序后,我们会遍历有序的Query文件,统计每个Query出现的次数,并再次写入文件。
综合分析,排序的时间复杂度为O(NlgN),遍历的时间复杂度为O(N),所以算法整体时间复杂度为O(N+NlgN)=O(NlgN)。
2)、哈希表方法(这个方法非常适合统计字符串出现的次数)
第一种方法中,我们使用排序的方法来统计每个Query出现的次数。时间复杂度为NlgN,那么有没有更好的方式以更低的时间复杂度来存储呢?
标题中说明了虽然有1000万个Query,但由于重复程度高,实际上只有300万个Query,每个Query都是255Byte,所以可以考虑全部放入内存。现在我们只需要一个合适的数据结构。这里,Hash Table绝对是我们的优先选择,因为Hash Table的查询速度非常快,时间复杂度几乎是O(1)。
那么,我们的算法是:
维护一个哈希表,其中键是查询字符串,值是查询出现的次数。每次读取Query时,如果该字符串不在Table中,则添加该字符串并将Value设置为1; if 如果字符串在 Table 中,则将字符串的计数加一。最终我们在O(N)的时间复杂度内完成了对这一海量数据的处理。
与算法1相比,该方法时间复杂度提高了一个数量级,为O(N),但不仅仅是时间复杂度上的优化,该方法只需要IO一次数据文件,而算法1 IO数量较多,因此算法2在工程上比算法1具有更好的可操作性。
第2步:查找Top 10(找到出现次数最多的10个)
算法1:普通排序(我们只需要找到top10,所以所有排序都存在冗余)
排序算法想必大家都很熟悉了,这里不再赘述。需要注意的是,排序算法的时间复杂度为NlgN。本题1G内存可以保存300万条记录。
算法2:部分排序
问题要求是找到Top 10,所以我们不需要对所有Query进行排序。我们只需要维护一个10个大小的数组,初始化10个Query,按照每个Query的统计数量从大到小排序,然后遍历这300万条记录。读取的每条记录都会与数组中的最后一个查询进行比较。如果小于这个Query,则继续遍历,否则,会将数组中最后一个查询的一条数据淘汰掉(仍然需要放在合适的位置并保持顺序)并添加到当前询问。最后,当所有的数据都遍历完之后,这个数组中的10个查询就成为我们要找的Top10了。
不难分析,这样一来,算法的最坏时间复杂度为N*K,其中K指的是top的数量。
算法3:堆
在算法2中,我们将时间复杂度从NlogN优化为N*K。不得不说,这是一个比较大的进步,但是还有更好的吗?解决办法是什么?
我们来分析一下。算法2中,每次比较完成后,所需的操作复杂度为K,因为需要将元素插入到线性列表中,并且采用顺序比较。这里让我们注意数组是有序的。每次我们查找的时候,都可以使用二分法来查找。这样,运算复杂度就降低到了logK。然而,随之而来的问题是数据移动,因为移动的数据数量增加了。不过这个算法相对于算法2还是有所改进的。
基于上面的分析,我们思考一下,是否有一种数据结构既可以快速查找元素又可以快速移动元素?
答案是肯定的,它是一堆。
借助堆结构,我们可以在日志时间内查找并调整/移动。所以此时我们的算法可以改进为这样,维护一个大小为K(本题为10)的小根堆,然后遍历300万个Query,分别与根元素进行比较。
思路与上述算法2一致,只不过算法3中我们使用最小堆等数据结构代替数组,降低了从O(K)查找目标元素的时间复杂度为 O(logK)。
本例中,使用堆数据结构和算法3,最终时间复杂度降低至N*logK。与算法2相比,有比较大的改进。
至此,算法就彻底结束了。经过上述第一步后,首先使用Hash表统计每个Query出现的次数,O(N);然后第二步,利用堆数据结构求Top 10,N* O(logK)。所以,我们最终的时间复杂度是:O(N) + N’*O(logK)。 (N 为 1000 万,N' 为 300 万)。
js如何利用堆实现Top K算法?
1。使用堆算法实现Top,时间复杂度为O(LogN)
function top(arr,comp){ if(arr.length == 0){return ;} var i = arr.length / 2 | 0 ; for(;i >= 0; i--){ if( comp(arr[i], arr[i * 2])){exch(arr, i, i*2);} if(comp(arr[i] ], arr[i * 2 + 1])) {exch( arr, i, i*2 + 1);} } return arr[0]; } 函数 exch(arr,i,j){ var t = arr[i]; arr[i] = arr[j]; arr[j] = t; }2。调用K次堆实现,时间复杂度为O(K * LogN)
function topK(arr,n,comp){ if(!arr || arr.length == 0 || n arr.length){ return -1; } } var ret = new Array(); for(var i = 0;i < n; i++){ var max = top(arr,comp); ret.push(最大); arr.splice(0,1);返回ret; }3。测试
var ret = topK(new Array(16,22,91,0,51,44,23),3,function (a,b){return a < b;});控制台.log(ret); 上面就是如何利用堆来实现Top K算法。 Top K算法是什么?希望对大家的学习有所帮助。