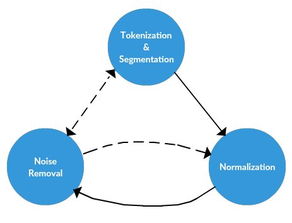
随着大数据时代的到来,文本数据在各个领域的应用越来越广泛。文本数据分析方法可以帮助我们挖掘文本中的有价值信息,为决策提供支持。本文将介绍文本数据分析的主要方法,包括文本预处理、特征提取与表示、文本分类与情感分析、文本聚类与关联分析等方面。

1. 数据清洗
数据清洗是文本预处理的重要步骤,主要包括去除重复数据、格式化数据、去除异常值等。数据清洗可以保证后续分析的准确性和稳定性。
2. 文本分词
文本分词是将原始文本转换为单词或词组的过程,是文本分析的基础。常见的分词方法有基于规则的分词、基于统计的分词和混合分词等。
3. 停用词去除
停用词是指在文本中出现频率较高但对文本内容贡献较小的词汇,如“的”、“和”等。停用词去除可以提高文本分析的效率和准确性。

1. 词袋模型
词袋模型是一种简单的特征提取方法,通过统计每个单词在文本中出现的次数来构建特征向量。词袋模型简单易懂,但忽略了单词的位置和顺序信息。
2. TF-IDF模型
TF-IDF(Term Frequecy-Iverse Docume Frequecy)模型是一种改进的词袋模型,通过引入逆文档频率来衡量单词的重要性。TF-IDF模型能够更好地反映单词在文本中的重要性。
3. 向量空间模型
向量空间模型是一种将文本表示为向量的方法,通过将文本中的单词转换为向量表示,可以方便地进行文本相似度计算和聚类分析。常见的向量表示方法有词嵌入(如Word2Vec、GloVe等)和矩阵分解(如SVD等)。

1. 基于规则的方法
基于规则的方法通过手动定义规则来对文本进行分类和情感分析。这种方法简单直观,但需要人工参与规则制定,且对于大规模的数据集效果不佳。
2. 基于机器学习的方法
基于机器学习的方法通过训练机器学习模型来进行文本分类和情感分析。常见的机器学习算法有朴素贝叶斯、支持向量机(SVM)、逻辑回归等。这些方法可以通过训练自动学习分类和情感分析的规则,但需要一定的数据量和标注数据。
3. 基于深度学习的方法
基于深度学习的方法利用神经网络对文本进行特征学习和表示,从而提高分类和情感分析的准确性。常见的深度学习模型有卷积神经网络(C)、循环神经网络(R)和长短期记忆网络(LSTM)等。这些方法在处理大规模的文本数据时具有较高的效果和鲁棒性。

1. 基于K-meas的聚类方法
基于K-meas的聚类方法是一种常见的聚类算法,通过将文本数据划分为K个簇来发现文本之间的相似性和差异性。K-meas算法简单易懂,但需要手动选择合适的簇数。
2. 基于层次聚类的方法
基于层次聚类的方法通过构建树状结构来对文本数据进行聚类,常见的层次聚类算法有BIRCH、CURE等。这些方法可以发现更复杂的文本相似性和差异性模式。