
文本分析算法是自然语言处理(LP)领域的一个重要分支,它通过对文本数据进行预处理、特征提取、模型训练、模型评估等步骤,实现对文本数据的深入理解和分析。本文将详细介绍文本分析算法的主要流程和关键技术,以期为读者提供有关文本分析算法的全面了解。

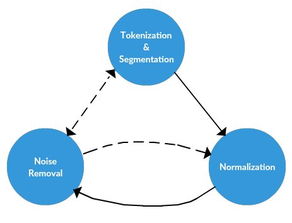
文本预处理是文本分析算法的第一步,其主要目的是将原始文本数据转化为适合后续处理的格式。预处理过程包括分词、去除停用词、词干提取等操作,以消除文本中的冗余信息,提取出有意义的词汇和短语。还需要对文本进行编码转换,以便将其输入到模型中进行训练。

特征提取是文本分析算法中的关键步骤,它通过对文本数据的特征进行提取和选择,为后续的模型训练提供输入。特征提取方法包括基于词袋模型的TF-IDF特征、基于词频统计的TF特征、基于语义相似度的TexRak特征等。选择合适的特征提取方法能够提高模型的准确性和泛化能力。

模型训练是文本分析算法的核心环节,它通过训练数据集对模型进行训练,使其能够自动学习文本数据的内在规律和模式。常用的模型包括朴素贝叶斯分类器、支持向量机(SVM)、神经网络等。选择合适的模型并调整其参数能够提高模型的性能和预测准确性。

模型评估是对已训练的模型进行评估的过程,以检验模型的预测能力和泛化能力。常用的评估指标包括准确率、召回率、F1值等。还可以通过交叉验证、留出验证等方法对模型进行评估。根据评估结果可以对模型进行调整和优化,以提高其性能。

结果分析是对模型预测结果进行解释和分析的过程。通过对预测结果的分析,可以了解模型的性能和存在的问题,从而对模型进行改进和优化。还可以通过结果分析挖掘文本数据中的隐含信息和规律,为后续的应用提供参考。

本文详细介绍了文本分析算法的主要流程和关键技术,包括文本预处理、特征提取、模型训练、模型评估和结果分析等方面。通过这些步骤,我们可以实现对文本数据的深入理解和分析。文本分析算法仍存在一些挑战和问题,如数据稀疏性、语义歧义性等。未来研究方向包括改进现有算法以提高性能和泛化能力、探索新的特征提取方法以适应不同场景的需求、以及研究跨语言和跨领域的文本分析技术等。
[此处列出参考文献]
[此处列出附录内容]