之前,计算机最初是设计用来做数学计算的。 Computer这个词的英文原义是“计算器”——在计算机发明之前,计算机是一个独立的职业,专门利用各种数学表格进行计算,例如测量和天文学领域的三角函数表和对数表,以及航海领域的航海星历表。
计算机发明后不久,人们发现这个东西除了可以作为计算器之外,还可以作为人类社会处理非数字信息的办事员。然而,计算机被设计为仅识别数字(具体来说,仅识别二进制数)。如果你想让它能够识别和处理人类的符号,就必须采用某种翻译方法。在计算机的二进制数和人类符号之间进行双向转换。
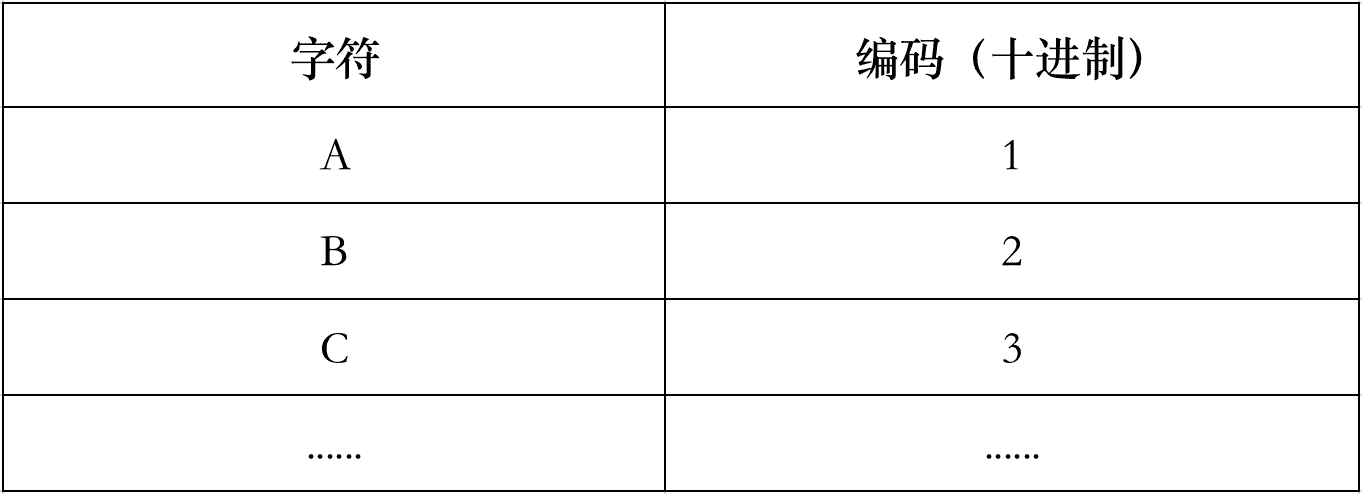
这个字符-数字映射(转换)关系本质上是一个查找表,理论上非常简单。我们首先给每个人物角色分配一个唯一的编号(角色代码),如图:

然后通过外围设备(键盘)将字符输入到计算机中。例如,我们的键盘上分别有 A、B、C 键。当我们按下“A”时,计算机从查找表中得知该字符的编码是十进制1,并在内部使用二进制00000001来表示和存储。
仅存储是不够的,我们还需要在计算机中显示或打印字符(数字),所以还涉及到字体库。在显示器上显示某个字符,本质上就是将一个n*n像素矩阵中的某些位置的像素设置为黑色(用1表示),将某些位置的像素设置为白色(用0表示),比如中文的“有”位图(请注意,不同的字体有不同的位图):
这样一个16*16的像素矩阵需要16 * 16 / 8 = 32字节的空间来表示。右边的“字形信息”称为字形编码。不同的字库(如宋体、黑体)对于同一个字符有不同的字形编码。
这里的每个像素只需要黑色和白色两种颜色,并且只需要一位。如果是颜色,理论上需要3个字节(RGB)来表示(当然这里不考虑压缩算法)。
所以这里涉及到另一个查找表: 字符编码-字形编码映射关系:

计算机根据用户指定的字体找到该字符编码对应的字体编码值,并发送给相应的图形处理程序,显示相应的字符。
整个输入-转码存储-输出(显示/打印)过程简单表述如下:

对于英文字符,直接在键盘上输入即可。对于其他字符,比如中文,就没那么直观了,因为键盘无论如何也装不下那么多汉字,所以还需要再一层转换。我们将计算机内部的字符编码称为内码,而外部用户使用的字符编码称为外码。例如,中文输入法使用的外码有拼音、五笔码、仓颉码等,这种情况下,还需要做外码到内码的映射。
文字处理系统需要考虑的东西很多,绝不是简单的编码映射。例如,文字处理系统需要能够正确处理特定的语言上下文,如英文单词的换行、英文单词的大写、中文的水平和垂直对齐、阿拉伯语的连字符处理等。
我们重点关注上图中的“字符编码”。
从今天的角度来看,世界上有各种各样的字符编码标准,比如ASCII、ISO-8859-1、GBK、Big5、Unicode等 - 你有没有想过单一的字符编码为什么会有这么多标准?这不是故意迷惑程序员吗?
现实中的标准从来都不是由权威机构预先制定的。相反,一些企业根据自己的需求(市场拓展需求)发明了一套游戏规则。每个公司都会根据自己的情况制定自己的游戏规则。每个公司之间的规则都不同。自己玩还好,一起玩就傻了(互通性)。所以要么是标准制定组织(如国标委、ISO等)站出来,要么是几个龙头企业联合起来,形成一定的联盟。总之,每个人都有一个目标:统一游戏规则。
套用鲁迅先生的话:这个世界上没有标准。当玩的人多了,它就成为一种标准。
只有从这个角度看问题,才能明白为什么有这么多的字符集编码标准,为什么会有Unicode,以及为什么Unicode的一些实现很奇怪。
1964年,IBM推出了划时代的大型机System/360(请告诉我它有多划时代)。为大型机设计的字符集编码标准称为EBCDIC(Extended Binary Coded Decimal Interchange Code,扩展二进制编码十进制交换码),这是一种单字节编码方案,包括一些控制字符、数字、常用标点符号及大小写英文字母:

EBCDIC 编码。图片来自百度百科
图中行号代表字节的高4位,列号代表字节的低4位,行列分别为十六进制0~F,例如0x81代表a,0xC1代表A、注意表中的英文单词不是连续的,这给程序处理带来一些麻烦。
四年后,美国国家标准学会ANSI(美国国家标准学会)发布了著名的ASCII(1968年美国信息交换标准码)编码标准。 ASCII 与 EBCDIC 一样都是单字节编码,但它借鉴了 EBCDIC 的经验教训,对英文单词分配连续编码,以方便程序处理。

ASCII 编码(注意此表中的列代表字节的高 4 位)。图片来自百度百科
其中前32个(031)是不可见的控制字符,32126是可见字符,127是DELETE命令(键盘上的DEL键)。
与 ASCII 和 EBCDIC 编码相比,除了拉丁字母连续排列外,ASCII 只使用一个字节的低 7 位,最高位始终为 0。因此 ASCII 最多可以表示 2^7 = 128 个字符,这对于当时的美国来说已经足够了。
不要低估最高位的0。这可以说是ASCII设计最成功的一个方面。后面我们讨论其他编码标准的时候,你会发现ASCII的标识符就是最高位的0。 ,其他编码标准可以与 ASCII 码无缝兼容,这又使得 ASCII 于 1972 年被 ISO/IEC 广泛接受并采用为国际标准(ISO/IEC 646),至今仍然是世界上最基本、最重要的。 ,最广泛使用的字符编码标准之一。
EBCDIC 用完了全部 8 位,理论上可以编码 2^8 = 256 个字符,但实际上很多数字没有对应的字符。如图所示,其中有几个不连续的“空洞区”,其编码远不如ASCII紧凑。由于EBCDIC的一些缺点,在ANSI推出ASCII编码标准后,IBM在其后续的个人计算机(PC)和工作站操作系统中不再使用自己的EBCDIC,而是使用ASCII。
1971 年,Intel 发布了 4004,世界上第一款微处理器。这是一个4位微处理器(现在是64位),10微米工艺(现在10纳米工艺以下),尺寸为3*4mm,工作频率为108KHz,每秒操作60,000次。

第一个微处理器Intel 4004
以今天的标准来看,这东西的计算能力并不高,但它的突破在于它的体积,只有几毫米见方。从当时的角度来看,可以用“微”来形容。
CPU体积的大幅缩小,使计算机的体积大大缩小,让计算机可以放在个人办公桌上,而不必呆在专用的机房里(想想第一台电子计算机ENIAC,占地170平方米,你我的房子都装不下)。另一个(但同样重要的)结果是计算机的生产成本变得更加便宜,这使得普通公司和个人可以拥有计算机。
所以微处理器诞生后的20世纪70年代和1980年代,是个人电脑的井喷时代。
1975 年,Edward Roberts 的 MITS 公司制造了世界上第一台微型计算机,Altiar 8800,仅售 397 美元(IBM 大型机系统/) 售价约为300 万美元)。

第一台微电脑Altiar 8800
注意:关于谁是第一台个人计算机和第一台微型计算机的说法是有争议的(甚至是微处理器),许多公司都声称自己是第一台,所以如果在其他地方寻找不同的答案,请不要感到惊讶。
另外,虽然今天我们认为个人拥有电脑是很正常的(没有电脑就很不正常),但在 20 世纪 70 年代初人们并不这么认为。很多企业的第一反应是:个人为什么需要电脑?许多公司由于认知限制而错过了个人电脑浪潮(例如施乐)。
1975 年,比尔·盖茨和保罗·艾伦创立了微软。
1976 年,史蒂夫·乔布斯和史蒂夫·沃兹尼亚克创立了苹果公司。
1981 年,推出IBM PC。 IBM PC 对整个行业产生了深远的影响。大公司批量购买它们,从那时起,个人电脑在办公室中发挥着越来越重要的作用。 IBM PC使用了微软开发的MS-DOS操作系统,微软声名鹊起。
8 {IMG_8: Ahr0CHM6LY9PBWCYMDiylmnuymxvz3Muy2JSB2CVMTK5NZC2MS8YMDIVMDIVMTK5NZC2MSDIMDIYMTQZODA2NC0XMJAZMZKWODC3L mpwzw ==/}1981 年发布的 IBM PC
——等等,我们不是在说字符编码吗?我们为什么谈论个人电脑?
如果没有个人电脑的普及,世界上就不会有这么多的字符集编码,甚至不需要Unicode。
System/360这样的大型机花费了数百万美元(相当于现在超过2000万美元)。它们仅被航天机构、银行、航空公司等用于小公司和个人消费。读者绝对不会买账——这样的话,即使需要多语言编码标准,也不会有那么多的字符集,很可能甚至不会有像Unicode这样的统一编码标准。
正是个人电脑的普及,让电脑在全世界范围内成为了日常办公用品。软硬件厂商在国际化过程中不可避免地会面临一个问题:原来的ASCII编码标准无法代表其他国家的语言。象征。
制造商在进入欧洲市场时遇到了困难。
欧洲主流语言虽然也使用拉丁字母,但有很多扩展名,比如法语中的é、挪威语中的Å,都无法用ASCII表示。
所以这些公司的技术人员发挥了他们的才能。大家发现在ASCII编码的字节中,最高位没有被使用(始终为0)。既然如此,为什么不使用这个位呢?这样,可以表示的字符数就多了128个。对于欧洲主流语言来说就足够了。
于是,各公司开始在ASCII的基础上扩展自己的字符集:当最高位为0时,仍然表示原来的ASCII字符不变,当最高位为1时,表示扩展字符——这就完美了。它与原始ASCII兼容,可以表达欧洲国家特有的字符。例如,IBM的代码页437用于编码主要欧洲语言字符(主要是西欧字符),代码页852编码东欧国家的拉丁字母,代码页855编码西里尔字符(如俄语)。 Microsoft 为 Windows 开发了代码页 1252,用于对西欧字符进行编码。苹果、施乐等也在开发自己的代码页标准。
这里有两个问题。首先,每个公司都制定自己的扩展编码,彼此不兼容;其次,即使增加128个字符,仍然不能表达所有的欧洲字符。
为了解决这两个问题,国际标准化组织ISO和IEC联合制定了一套标准,称为ISO/IEC 8859(简称ISO 8859)。注意,ISO 8859并不是一套具体的字符集编码标准,而是一组字符集的统称,称为ISO/IEC 8859-n,n=1,2,3,...,15,16(其中 12 未定义,因此总共 15)。
这些字符集编码标准都是单字节编码。前128个字符编码(最高位为0)与ASCII相同,后128个字符分配给不同的语系。 ISO 8859 的每种编码都与 ASCII 兼容,但彼此不兼容(即 0~127 范围内的每个都代表相同的字符,而 128~255 的每个代表各自系统中的字符)。
使用最广泛的是ISO/IEC 8859-1,也称为拉丁语1,包含西欧常用字符,包括德语、意大利语、葡萄牙语、和西班牙语。等等(由于拉丁语 1 中没有法语字符 œ、Œ 和 Ÿ,因此法语使用 ISO 8859-15 字符集)。

ISO/IEC 8859-1字符集,注意007F之前与ASCII一致
上面提到的字符Å在这里用00C5表示。
ISO 8859-2至ISO 8859-16剩余字符如下(部分):
ISO/IEC 8859-1 (Latin-1) - 西欧语言
ISO/IEC 8859-2 (Latin-2) - 中欧语言
ISO/IEC 8859-3 (Latin-3) - 南欧语言。
ISO/IEC 8859-4 (Latin-4) - 北欧语言
ISO/IEC 8859-5(西里尔文)- 西里尔文语言
ISO/IEC 8859-6(阿拉伯语)- 阿拉伯语
ISO/IEC 8859-7(希腊语)- 希腊语
......
当这些制造商进入东亚市场时,他们有更大的领先优势。
在欧洲,他们能够使用为 ASCII 高位保留的字节制定 ISO 8859 系列标准。然而,当他们面对数以万计的汉字时,却有些困惑了。
对于中日韩等表意字符,单字节编码根本不行,必须使用两个字节。针对日本,制定了Shift JIS标准;对于繁体中文,Big5标准是由台湾相关行业协会于1984年制定的;简体中文GB 2312由国家标准总局于1980年制定。
作为一名中国大陆公民,我们来稍微深入地谈谈GB系列编码标准。
原标准为《信息交换用汉字编码字符集》,是国家标准总局于1980年发布的一套国家标准,1981年5月1日实施,标准号为GB 2312-1980。它包含6763个汉字,以及682个字符,其中包括拉丁字母、希腊字母、日语平假名和片假名字母以及俄语西里尔字母。
GB 2312 是双字节编码。为了兼容ASCII码,GB 2312规定汉字必须用两个字节表示,且值大于127(最高位为1);反之,如果一个字节的值小于或等于127(最高位为1,位为0),那么它与ASCII码表示的字符相同(即是ASCII码)此时)。
也就是说,在GB 2312中,英文字母(以及ASCII中的标点符号)占用1个字节,汉字占用2个字节。
我们用python程序来验证:
>>>>字节("A","GB 2312")
巴阿
>>> 字节("啊", "GB 2312")
b'\xb0\xa1'
上面的字母“A”占用1个字节,字符“ah”占用两个字节(字节值为B0 A1,两个字节的最高位都是1,其中B0称为高位字节, A1 称为低位字节)。
也就是说,GB 2312是变长编码,用1~2个字节来表示字符,字节的最高位的值决定了字符占用的字节数。

GB 2312编码表(部分)
需要注意的是,GB 2312中对“(1)”、“(一)”等组合字符赋予单独的编码(即,将它们视为一个字符而不是多字符组合),这会影响后续的Unicode字符集设计。
GB 2312 使用区号方法进行编码。这种编码方法将一个矩形区域划分为94行×94列,总共形成8836个94×94的网格,然后将字符填充到这些网格中。
行和列从 1 开始编号。行称为 区域 ,列称为 位 。这样就形成了1~94个区域,每个区域有94位。字符由区号+位数表示。

位置矩阵示意图。注意图中的位置编号是用十进制表示的
地点:
01~09区域(682个):特殊符号、数字、英文字符、制表符等,包括682个拉丁字母、希腊字母、日语平假名和片假名字母、俄语西里尔字母等全角字符;
区域10~15:空区域,预留扩展;
16~55区(3755个):常用汉字(又称一级汉字),按拼音排序;
56~87区(3008):非常常用的汉字(也称次要汉字),按部首/笔画排序;
区域88~94:空区域,预留扩展。
比如“啊”字的区号是16,位数是01,十六进制表示的区号是10 01,我们不是说汉字使用两个字节吗?然后我们将 10 放入第一个字节(高位字节),将 01 放入第二个字节(低位字节)——这是不对的!两个值都小于128。根据前面的说法,表示汉字的两个字节的最高位必须为1,也就是说转换成数值必须大于127。另外,我们用python代码输入的“ah”这个词的字节值显然是B0 A1。
所以这个位置代码仅供人类查看。它是一个逻辑数。它不等于计算机中的实际存储表示。
当区号以计算机字节表示时,必须进行某种转换——至少使其大于127。区位码本身都小于128(最大只有94),因此最高位它们的原始字节码全部为0。我们只需将最高位更改为1——即与原始值相加。只要达到 2^7 = 128 即可。
但是这样得到的值并不是最终的字节编码值。计算机中最终的字节编码值需要在此基础上加上32(至于为什么加32,一般原因是GB 2312想要修正,将ASCII中的可见字符重新编码为双字节全字节) width 编码,但必须排除那些不可打印的控制字符和空格,所以必须将原来的位置码向后移 32 位(如果有兴趣了解详细信息,请自行百度)。也就是说,位置码必须加上 128 + 32 = 160(十六进制 A0)才能成为机器字节码——为了与原来的位置码区别,这个字节码有了一个新名字,叫做 Code 。
我们来计算一下汉字“啊”的内码。高位字节:16+160=176,转换为十六进制为B0;低位字节:01 + 160 = 161,转换为十六进制是A1,即“啊”字的内码是B0 A1,与前面python程序的输出一致。
我们平时所说的某个汉字的GB 2312编码值一般指的是内码。
1 {IMG_12:Ahr0Chm6ly9pbwcymdiylmnuymxvz3Muy29tl2jsb2cvmtk5NZC2MS8ymdiymdiVMTK5NZC2MSDIYMDIYMTQZNZKXMTYYMDU111 Lmpwzw ==/}三个代码值对照表。原来的区位代码加上32后的值也有了一个新名字,叫做“国标代码”
GB 2312仅收录了6763个汉字。虽然可以满足99%以上的使用场景,但是无法处理一些生僻字符(比如一些人名、古文字)。另一个问题是GB 2312不支持繁体中文字符。
所以1995年颁布《汉字内码扩展规范》(GBK,国标国展的缩写,是GB 2312-1980的延伸)。 GBK完全兼容GB 2312,包含Big5中的所有繁体汉字以及GB 2312中未包含的其他汉字,共计21003个汉字。
GBK也是双字节编码。问题来了。 GB 2312要求两个字节的最高位必须为1,最多只能表示2^14 = 16384个字符——不够。所以GBK只要求汉字的第一个字节(高位字节)的最高位必须为1,第二个字节(低位字节)的最高位可以为0。
随着国际字符集编码标准ISO/IEC 10646和Unicode的不断发展,收录的字符越来越多,而GBK总共只有2万多个字符(主要是汉字),有点落后时代。
我国在GBK制定后的第五年(2000年)制定了新标准GB 18030-2000,以取代GBK标准。 GB 18030-2000是强制性标准(GBK只是指导性的),这意味着在中国大陆销售的软件必须支持GB 18030-2000标准。
GB 18030的目标是与Unicode/UCS对齐(而GBK只是GB 2312到Unicode对齐过程中的一个过渡标准)。 2000版GB 18030在GBK的基础上增加了CJK统一汉字扩展A(CJK)的汉字,GB 18030-2005在GBK的基础上增加了CJK统一汉字扩展B的汉字。以GB 18030-2000为基础,包含7万多个汉字。此外,GB 18030-2005还包括多种中国少数民族语言(如藏语、蒙古语、傣语、彝语、朝鲜语、维吾尔语等)。
不可否认,2 个字节已经不够了。 GB 18030 包含三种长度编码:单字节 ASCII、双字节 GBK(有轻微扩展)和用于填充所有 Unicode 代码点的四字节 UTF 块。 GB 18030与GBK完全兼容,其码位足以覆盖所有Unicode编码空间。
注意GB 18030-2005是部分强制的——其中包含的GB 18030-2000部分是强制的,在中国大陆销售的相关软件必须支持该部分。
我们知道,早期的软硬件厂商(IBM、微软、苹果等)在进入不同区域市场时,会针对特定区域的语言和文本分别制定一套字符集编码标准,因此这些厂商内部会有很多套标准。这些字符集编码标准通过内部不同的数字进行标识,并被命名为代码页(代码页,也称为内部代码表)。
每个制造商都有自己的一组代码页。这些代码页仅供其内部使用。虽然它们基本上与 ASCII 兼容,但不同的代码页(包括同一制造商内部和制造商之间)并不相互排斥。兼容的。例如IBM针对欧洲市场的codepage 437(西欧拉丁字母)、852(东欧拉丁字母)、855(西里尔字母)等;微软的代码页1251(西里尔字母)、1252(西欧拉丁字母)、1253(希腊字母)等。
后来,一些标准化组织(如 ISO、ANSI、中国国家标准局)和联盟(如 Unicode 联盟)参与了多项标准的制定后,厂商也将这些标准纳入了自己的代码页系统中。例如,GB 2312 的 Microsoft 代码页编号为 936,Big5 为 950,UTF-8 为 65001,UTF-32 LE 为 12000,UTF-32 BE 为 12001。
我们发现UTF-8和UTF-32是Unicode字符集编码标准的不同实现,并且在代码页系统中被分配了不同的编号(即UTF-8、UTF-32 LE、UTF-32 BE属于到不同的代码页)。换句话说,代码页中的编码是计算机实际的字节码,即字符在计算机中如何用字节来表示。这种编码称为“内部代码”——这也是代码页的名称。 “内码表”的由来。
字符编码有不同层次的表示,大致分为逻辑(人类看到的)和存储(计算机看到的)。比如我们前面提到的GB 2312的位置码就是逻辑级别的编码,而内码则是存储级别的。例如“Ah”的位置码为(十六进制)10 01,内码为B0 A1。 Microsoft 代码页 936 中单词“ah”的编码是 B0 A1。 “啊”这个词的 Unicode 编码是 U+554A。这种(逻辑级别)编码通过 UTF-8 和 UTF-32 的表达方式不同。 UTF-8编码为E5 95 8A,UTF-32 BE编码为00 00 55 4A,UTF-32 LE编码为4A 55 00 00(BE表示大端表示法,LE表示小端表示法)。
此外,代码页和某些标准不一定完全等效。往往因为有些标准不能满足厂商的具体需求,厂商会在标准的基础上进行一些扩展,将标准合并到代码页中。放。例如,Microsoft 的代码页 1252 对应于 ISO/IEC 8859-1 (latin 1) 并进行了扩展。
另一方面,由于某些制造商的产品被广泛使用,因此他们指定的代码页也被其他制造商的产品所支持。例如,由于IBM PC在商业上取得了巨大的成功,微软的MS-DOS操作系统依赖于其捆绑销售,所以我们打开微软的代码页列表,看到里面有大量的IBM代码页。例如,Microsoft 的代码页 437 就是相应的 IBM 代码页。 437,其中许多带有“OEM”描述的基本上都是 IBM 代码页。有关详细信息,请参阅:https://www.sychzs.cn/en-us/windows/win32/intl/code-page-identifiers。

Microsoft 对 IBM 代码页的支持(部分)
当您在Windows上保存记事本文件时,您会在编码栏中发现一种名为ANSI的编码方式:

ANSI 是美国国家标准协会。它是一个组织。微软把它作为一种编码方法放在这里确实令人困惑。这需要了解它的历史。
当 Microsoft 开发 Windows 操作系统时,美国国家标准协会 ANSI 正在制定西欧文字的 ASCII 扩展草案(后来被 ISO/IEC 接受为 ISO/IEC 8859-1 标准)。微软根据草案开发了代码页,codepage 1252,用于对西欧字符进行编码(注意,微软根据草案开发了代码页,而当时 ISO/IEC 8859-1 尚未向公众发布。代码页 1252 是 ISO/IEC 8859-1 超集)。微软将这个代码页称为“ANSI代码页”(微软官方网站将代码页1252描述为“ANSI Latin 1;西欧(Windows)”)。
也就是说,微软所说的ANSI编码最初指的是它根据ANSI Latin 1草案开发的codepage 1252。
后来 Unicode 出现了,微软的新版本 Windows 很快就支持了 Unicode(最开始是以 UTF-16 的形式,所以你在微软的编码选项里面会看到一项“Unicode”编码项,就是指 UTF-16 编码)。为了和 Unicode 编码相区分,在 Windows 95 以及后续版本中,“ANSI 编码”的含义已经不再单指 codepage 1252 了,而是指所有的非 Unicode 编码方案——也就是说它不再表示一个代码页,而是表示一组代码页,具体表示哪个取决于系统设置,比如简体中文环境就表示 codepage 936(GB2312)。
我们上面讨论的这些编码标准(ASCII、ISO/IEC 8859 系列、GB 系列、Big5 以及各软硬件厂商自己制定的标准)都存在两个问题:
以上问题导致的结果是,一个软件要想用在不同语言的市场,就得同时支持多种编码方式,特别在早期,这些工作都是各自厂商自己在做,耗费了大量的人力财力,而且还要不停地更新各种编码标准。另外,由于各厂商对同一个语系的字符采用了不同的编码标准,同样一个法语文件,在软件 A 中打开正常,在软件 B 中可能就是乱码,虽然 A 和 B 都支持法语字符。
总之,在很长一段时间,技术人员一边要不厌其烦地开发、更新、兼容各种字符集编码,另一方面又要受着各种乱码问题的折磨。
直到 1987 年的某一天,这帮人中的几个终于忍无可忍,凑到一起,决定开发一套能容纳全世界所有字符的标准,一统天下。
在下一篇文章中,我们将聊聊这个能“一统天下”的新编码标准:Unicode。
原文链接:《字符集编码(上):Unicode 之前》