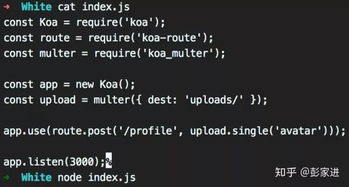
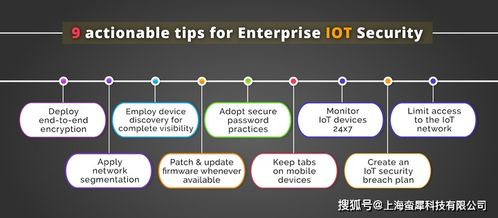
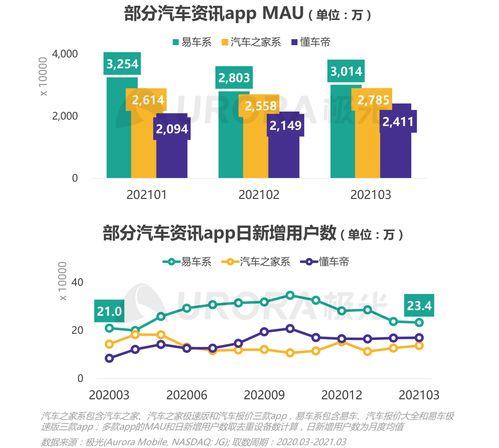
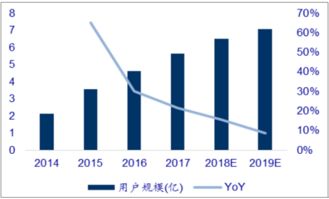
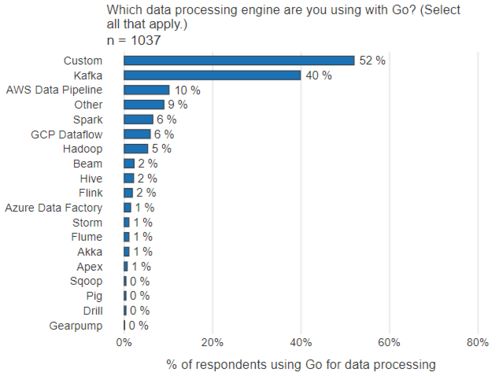
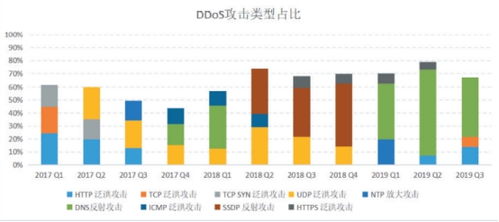
数据预处理是任何机器学习任务的关键步骤,其中包括数据清理、规范化、处理缺失值等。在进行文本分类之前,必须将原始文本数据进行预处理,将其转换为机器学习算法可以理解和使用的格式。例如,可以使用分词器将文本分解为单词或短语,并使用停用词过滤器去除无用的词汇。
特征提取
特征提取是将原始数据转换为机器学习算法可以使用的特征的过程。对于文本数据,特征通常可以是单词、短语、-grams等。在提取特征时,需要选择适当的特征提取方法,例如词袋模型、TF-IDF等方法,以从文本中提取有意义的特征。
分类器选择
分类器是用于将输入数据分配给预定义类别的算法。在文本分类中,常见的分类器包括朴素贝叶斯分类器、支持向量机(SVM)、决策树和神经网络等。选择适当的分类器对于分类任务的性能至关重要。
模型训练与优化
在选择适当的分类器后,需要使用训练数据对其进行训练,并使用验证数据对其进行优化。在这个过程中,可以使用各种优化算法和技术来改进分类器的性能,例如网格搜索、随机搜索、贝叶斯优化等。
分类结果评估
分类结果评估是衡量分类器性能的过程。常见的评估指标包括准确率、召回率、F1得分等。通过评估指标,可以了解分类器的性能,并根据需要进行调整和优化。
分类结果应用
分类结果应用是将分类器应用于实际问题的过程。例如,可以使用分类器对新的文本数据进行分类,以实现垃圾邮件过滤、情感分析、主题分类等应用。在应用过程中,需要注意处理未知类别的数据和过拟合问题。