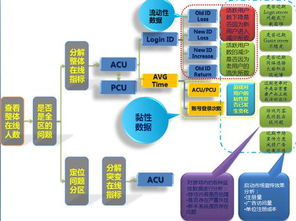
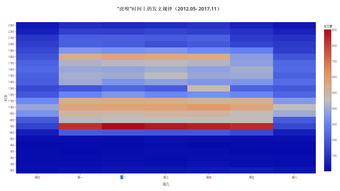
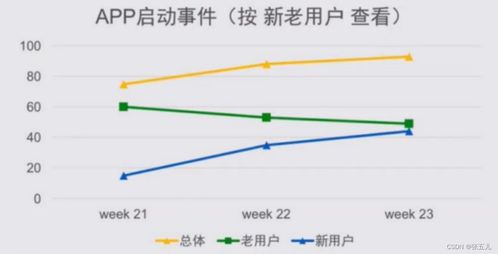
在文本数据分析中,数据收集和预处理是至关重要的第一步。我们需要确定我们的数据源,这可以是一组文本文件、网页、社交媒体平台或者其他文本输出。然后,我们需要进行数据清洗,以消除任何无关紧要的信息,例如广告、非标准字符等。这个过程包括去除空白字符、标点符号、停用词等,以得到结构化、标准化的数据。

在预处理之后,我们需要从文本中提取特征。这些特征可以包括词频、词向量、命名实体等。词频是一个词在文本中出现的次数,反映了文本的主题和语义。词向量是一种将词语转换为机器可读的形式的方法,例如Word2Vec或GloVe。命名实体是文本中具有特定意义的实体,例如人名、地名、组织等。这些特征可以帮助我们更好地理解和表示文本数据。

在提取特征之后,我们需要训练模型。常见的模型包括神经网络、决策树、贝叶斯网络等。其中,神经网络模型,特别是深度学习模型,在文本数据分析中得到了广泛应用。例如,循环神经网络(R)、长短期记忆网络(LSTM)、Trasformer等都可以用于文本生成和分类任务。我们可以通过调整模型参数,例如学习率、隐藏层大小、批量大小等,来优化模型的性能。

我们可以用训练好的模型来进行文本生成和应用。这可以包括各种任务,例如情感分析、主题分类、文本摘要、机器翻译等。情感分析可以根据文本的情感倾向进行分类,例如正面、负面或中立。主题分类可以将文本分类到预定义的主题类别中,例如新闻、科技、娱乐等。文本摘要可以生成简短的文本摘要,以帮助用户快速了解文本内容。机器翻译可以将文本从一种语言翻译成另一种语言。这些应用可以帮助我们更好地理解和处理文本数据,提高我们的工作效率和准确性。