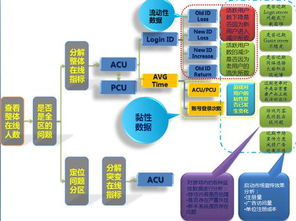

数据预处理是文本数据分析过程中的重要步骤,它主要包括数据清洗、分词、词性标注等。数据清洗的目的是去除无效数据、噪声数据以及重复数据,提高数据质量。分词是将文本分割成单个词语或短语的过程,便于后续的特征提取。词性标注是对每个词语赋予其对应的词性,如名词、动词、形容词等,有助于理解文本的语法结构和含义。

文本表示是将文本转化为计算机可处理的形式,常用的方法有词袋模型、TF-IDF(词频-逆文档频率)等。词袋模型是一种基于统计的方法,它将文本中的词语作为特征,统计每个词语出现的次数,然后将其转化为向量形式。TF-IDF是一种更为复杂的文本表示方法,它考虑了词语在文档中的出现频率和文档的长度,能够更准确地反映词语在文档中的重要性。

文本分类是将文本分为不同的类别,它是文本数据分析中的重要任务之一。常用的分类算法包括朴素贝叶斯、支持向量机、决策树等。这些算法通过学习已知类别的样本数据,自动提取文本的特征,并建立分类模型。然后,对于未知类别的文本,可以使用这些模型进行分类。

文本聚类是将相似的文本聚集在一起,它是文本数据分析中的另一个重要任务。常用的聚类算法包括K-meas、层次聚类等。这些算法通过计算文本之间的相似度或者距离,将相似的文本聚集在一起,形成不同的簇。聚类分析可以用于发现文本数据的分布模式,也可以用于文档的自动分类和组织。

文本摘要是对大量文本数据进行简化处理的过程,它能够自动提取关键信息并形成简短的摘要。常用的摘要方法包括基于规则的方法和基于机器学习的方法。基于规则的方法根据预定义的规则和模式对文本进行简化处理,而基于机器学习的方法则通过学习大量的摘要数据来自动提取文本特征并生成摘要。

文本生成是利用机器学习算法自动生成符合语法规则和语义逻辑的文本,它是自然语言处理领域的一个重要方向。常用的生成方法包括基于循环神经网络(R)的方法和基于变换器(Trasformer)的方法。基于R的方法通过学习输入序列的依赖关系来生成新的输出序列,而基于Trasformer的方法则通过多头自注意力机制和位置编码来学习输入序列中的长距离依赖关系。
文本数据分析技术是自然语言处理领域的重要研究方向之一,它涵盖了多个方面的任务和应用场景。通过对这些技术的理解和应用,我们可以更好地处理和理解大量的文本数据,为机器学习和人工智能的发展提供有力的支持。