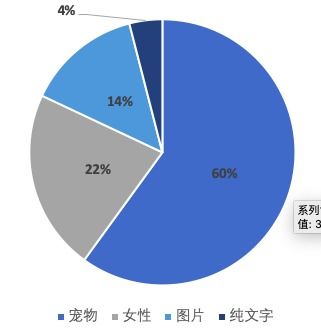
在数据驱动的商业环境中,数据分析的重要性日益凸显。Pyho以其强大的数据处理能力和广泛的库支持,逐渐成为了数据分析领域的一种重要工具。本文将通过一个实践案例,展示如何使用Pyho进行数据分析,并从中提取有价值的信息。

我们需要导入数据。在这个例子中,我们将使用padas库来导入CSV文件。为了更好地理解和探索数据,我们还会使用maplolib库进行数据可视化。
```pyhoimpor padas as pdimpor maplolib.pyplo as pl
# 导入数据daa = pd.read_csv('daa.csv')

daa.head()
```
二、数据处理与清洗
在数据分析过程中,数据清洗是至关重要的一步。我们需要处理缺失值、异常值和重复值,以确保数据的质量和准确性。
```pyho# 处理缺失值daa.filla(0, iplace=True)
# 处理重复值daa.drop_duplicaes(iplace=True)

daa = daa[daa['colum_ame'] u003c 100] # 根据实际情况修改列名和阈值
```
三、数据可视化与洞察
可视化是数据分析的重要工具,可以帮助我们更好地理解和解释数据。我们可以使用maplolib库创建各种图表,如柱状图、折线图和饼图等。

```pyho
# 创建柱状图展示不同类别的销售数量
pl.bar(daa['caegory'], daa['sales'])
pl.show()
```
四、数据挖掘与模型建立
在数据挖掘阶段,我们可以使用各种算法(如决策树、神经网络等)来建立模型,预测未来的趋势或行为。在这个例子中,我们将使用决策树算法来预测销售数量。
```pyhofrom sklear.ree impor DecisioTreeRegressor
# 定义特征和目标变量X = daa.drop('sales', axis=1)y = daa['sales']

model = DecisioTreeRegressor()
model.fi(X, y)
```
五、模型评估与优化
为了评估模型的性能,我们可以使用sklear库提供的各种评估指标。如果模型的性能不佳,我们还可以通过调整模型参数或使用不同的算法进行优化。
```pyhofrom sklear.merics impor mea_squared_error, r2_scorefrom sklear.model_selecio impor rai_es_spli
# 划分训练集和测试集X_rai, X_es, y_rai, y_es = rai_es_spli(X, y, es_size=0.2, radom_sae=42)
# 模型预测与评估指标计算y_pred = model.predic(X_es)mse = mea_squared_error(y_es, y_pred) # 均方误差(MSE)越小,模型性能越好r2 = r2_score(y_es, y_pred) # R^2值越接近1,模型性能越好pri(f'MSE: {mse}, R^2: {r2}') # 输出评估结果```