翻译 | 李锐
审稿人 |重楼
事件驱动架构 (EDA) 是一种软件设计模式,专注于事件的生成、检测和消费,以支持高效且可扩展的系统。在 EDA 中,事件是组件之间通信的主要方式,允许它们实时交互并响应变化。这种架构促进了松散耦合、可扩展性和响应能力,使其成为现代、分布式和高度可扩展的应用程序的理想选择。 EDA 已成为在现代系统中实现敏捷性和无缝集成的强大解决方案。
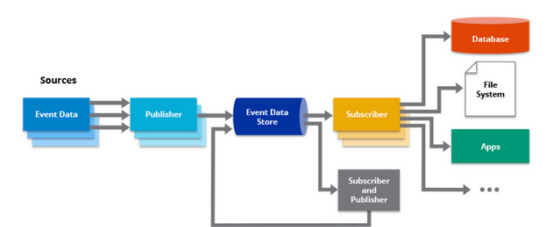
在事件驱动架构中,事件代表系统中的重要事件或变化,这些事件可以由各种来源生成,例如用户操作、系统进程或外部服务。称为事件生成器的组件将事件发布到中央事件总线或代理,充当事件分发的中介。其他组件称为事件消费者,它们订阅感兴趣的特定事件并做出相应的反应。
EDA 的一个关键优势是其支持敏捷性和灵活性的能力。事件驱动系统中的组件可以独立发展,从而更容易维护、更新和可扩展。可以通过引入新事件类型或订阅现有事件来添加新功能,而不会影响整个系统。这种灵活性和可扩展性使 EDA 特别适合动态和不断变化的业务需求。
EDA 还促进不同系统或服务之间的无缝集成。通过使用事件作为通信机制,EDA 支持互操作性,无论底层技术或编程语言如何。事件为系统交换信息提供了一种标准化且松散耦合的方式,使企业能够更轻松地集成不同的系统。这种集成方法促进了模块化和可重用性,因为可以在不中断整个系统的情况下连接或断开组件。
EDA 由几个在系统内启用事件流和处理的关键组件组成。这些组件协同工作以促进事件的生成、分发、消费和处理。以下是 EDA 的关键组件:
(1) 活动制作者
事件生产者负责生成和发布事件。它们可以是系统内的各种实体,例如用户界面、应用程序、微服务或外部系统。事件生成器捕获重要事件或更改并将事件发送到事件总线或代理。这些事件可以由用户操作、系统事件、传感器数据或任何其他相关源触发。
(2) 事件总线/代理
事件总线/代理充当事件的中央通信通道。它接收事件生产者发布的事件并将其分发给感兴趣的事件使用者。事件总线/代理可以是消息队列、发布/订阅系统或专门的事件流平台。它确保可靠的事件传递,将事件生产者与事件消费者解耦,并支持异步事件处理。
(3) 事件消费者
事件消费者订阅特定事件或感兴趣的事件类型。他们从事件总线/代理接收事件并相应地处理它们。事件使用者可以是系统中的各种组件,例如微服务、工作流或数据处理器。它们通过执行业务逻辑、更新数据、触发进一步的操作或与其他系统通信来响应事件。
(4) 事件处理程序
事件处理程序负责处理事件使用者接收到的事件。它们包含根据事件内容执行特定操作的业务逻辑和规则。事件处理程序可以执行数据验证、状态更改、数据库更新、触发通知或调用其他服务。它们封装与特定事件相关的行为并确保系统内正确的事件处理。
(5) 事件存储
事件存储是一个持久性数据存储组件,记录系统中所有已发布的事件。它提供事件及其相关数据的历史记录。事件存储支持事件重放、审计和事件溯源模式,允许系统根据过去的事件重建其状态。它支持事件驱动架构中的可扩展性、容错性和数据一致性。
第3步:创建Kafka主题
将 Kafka 中的主题定义为事件通信的渠道。根据预期负载和数据需求仔细规划主题结构、分区策略、复制因子和保留策略。确保一致的主题和事件粒度并支持未来的可扩展性。
第 4 步:设计事件消费者
确定将使用和处理 Kafka 事件的组件或服务。设计订阅相关主题并执行实时处理的事件消费者。考虑所需的消费者数量并相应地设计消费者应用程序。
创建消费者的示例 Python 代码:
Python
从 kafka 导入 KafkaConsumer
# 卡夫卡代理配置
bootstrap_servers = '本地主机:9092'
# 创建Kafka消费者
消费者= KafkaConsumer(bootstrap_servers = bootstrap_servers)
# 定义消费消息的主题
主题 = '测试主题'
# 订阅主题
消费者.订阅(主题=[主题])
# 开始消费消息
对于消费者中的消息:
# 处理消费的消息
print(f"收到消息:{message.value.decode('utf-8')}")
# 关闭消费者
消费者.close()
第 5 步:实现事件处理逻辑
在用户应用程序中编写事件处理逻辑。这可能涉及数据转换、丰富、聚合或任何其他特定于业务的操作。利用 Kafka 的消费者组功能在多个实例之间分配处理负载并确保可扩展性。
第 6 步:确保容错
实施容错机制来处理故障并确保数据持久性。使用适当的复制因子配置 Kafka 代理以提供数据冗余。在消费者应用程序中实现错误处理和重试机制来处理异常。
第 7 步:监控和优化性能
设置监控和可观察性工具来跟踪 Kafka 集群和事件驱动应用程序的运行状况和性能。监控吞吐量、延迟和消费者延迟等关键指标,以识别瓶颈并优化系统。考虑利用 Kafka 的内置监控功能或与第三方监控解决方案集成。
第 8 步:与下游系统集成
确定事件驱动架构如何与下游系统或服务集成。设计连接器或适配器以实现从 Kafka 到其他系统的无缝数据流。探索 Kafka Connect,这是一个用于与外部数据源或接收器集成的强大工具。
第 9 步:测试和迭代
彻底测试 EDA,确保其可靠性、可扩展性和性能。执行负载测试以验证不同工作负载下的系统行为。根据测试结果和实际反馈迭代和改进设计。
第 10 步:扩展和成长
随着系统的增长,监控其性能并相应地进行扩展。添加更多 Kafka 代理、调整分区策略或优化消费者应用程序以处理增加的数据量。
Kafka EDA 由于其处理高吞吐量、容错和实时数据流的能力,在各个领域都有各种应用。以下是 Kafka 擅长的一些常见用例:
实时数据处理和分析:Kafka处理大容量、实时数据流的能力使其成为处理和分析大规模数据的理想选择。用户可以将多个来源的数据提取到 Kafka 主题中,然后使用 Apache Flink、Apache Spark 或 Kafka Streams 等流框架实时处理和分析数据。该用例在实时欺诈检测、监控物联网设备、点击流分析和个性化推荐等场景中非常有价值。
这些只是 Kafka EDA 可应用的广泛用例的几个示例。其灵活性、可扩展性和容错能力使其成为处理流数据和构建实时事件驱动应用程序的多功能平台。
Kafka EDA 彻底改变了用户处理数据流和构建实时应用程序的方式。凭借其处理高吞吐量、容错数据流的能力,Kafka 实现了可扩展和解耦的系统,从而增强了灵活性、自治性和可扩展性。无论是实时数据处理、微服务通信、日志聚合、消息集成还是物联网应用,Kafka 的可靠性、可扩展性和无缝集成能力使其成为构建 EDA 架构的强大工具,可以驱动实时洞察并使用户能够利用他们的数据的价值。
原标题:使用 Kafka 构建事件驱动架构,作者:Rama Krishna Panguluri