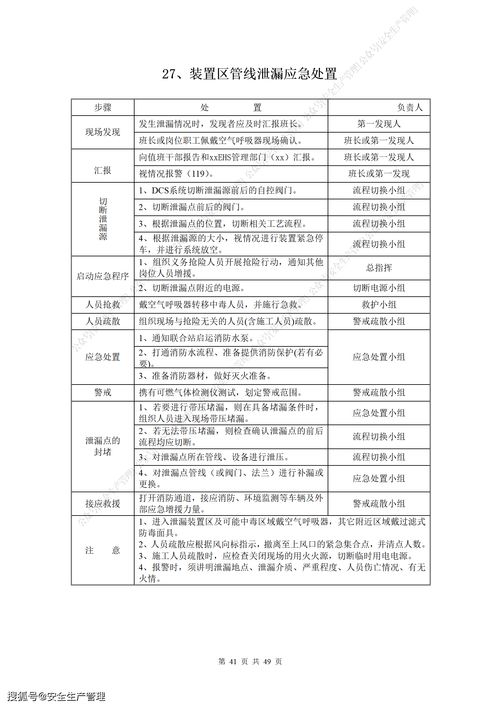
1. 生成高质量数据
GA可以通过训练生成器来生成高质量的数据。由于GA采用了深度学习技术,因此它可以学习到真实数据的潜在分布,从而生成与真实数据相似度非常高的样本。这使得GA在各种任务中都能够生成高质量的数据,如图像生成、音频生成等。
2. 强化学习
GA中的生成器和判别器之间的竞争关系可以被视为一种强化学习。在这种学习中,生成器需要不断改进自己的策略,以使得生成的样本能够更好地欺骗判别器。这种强化学习的方式可以使得GA在训练过程中更加稳定,并且能够更好地适应各种任务。
3. 多样化的数据生成
GA可以生成多样化的数据。由于GA学习到了真实数据的潜在分布,因此它可以生成与真实数据相似度非常高的样本,但是这些样本并不完全相同。这使得GA可以用于各种任务中,如数据增强、风格迁移等。
4. 无需手动标记数据
GA不需要手动标记数据,这大大减少了人工参与的程度。在传统的机器学习中,需要人工对数据进行标签化处理,这既耗时又耗力。而GA可以通过自我学习的过程来生成数据,从而避免了手动标记数据的繁琐过程。
5. 可解释性强
GA的可解释性强是其重要的优点之一。由于GA采用了深度学习技术,因此它可以对数据进行深层次的特征提取和表示学习。这使得GA在生成数据时可以更好地理解数据的内在特征和规律,从而提高了其可解释性。GA还可以用于各种任务中,如图像分类、语音识别等,其生成的样本也可以被用于各种应用中,如图像合成、语音合成等。
GA具有生成高质量数据、强化学习、多样化的数据生成、无需手动标记数据以及可解释性强等优点。这些优点使得GA在各种领域中都得到了广泛的应用和关注。随着GA技术的不断发展,相信其在未来的应用中将会更加广泛和深入。