数据分片是指将数据按照一定的方式存储在不同的服务上,以解决单机服务能力不足的问题。
本文主要围绕Redis,介绍逻辑分片、随机分配、哈希取模、一致性哈希等分片算法的原理和使用场景。并在此基础上比较客户端分片、代理(Proxy)和Redis集群的优缺点。
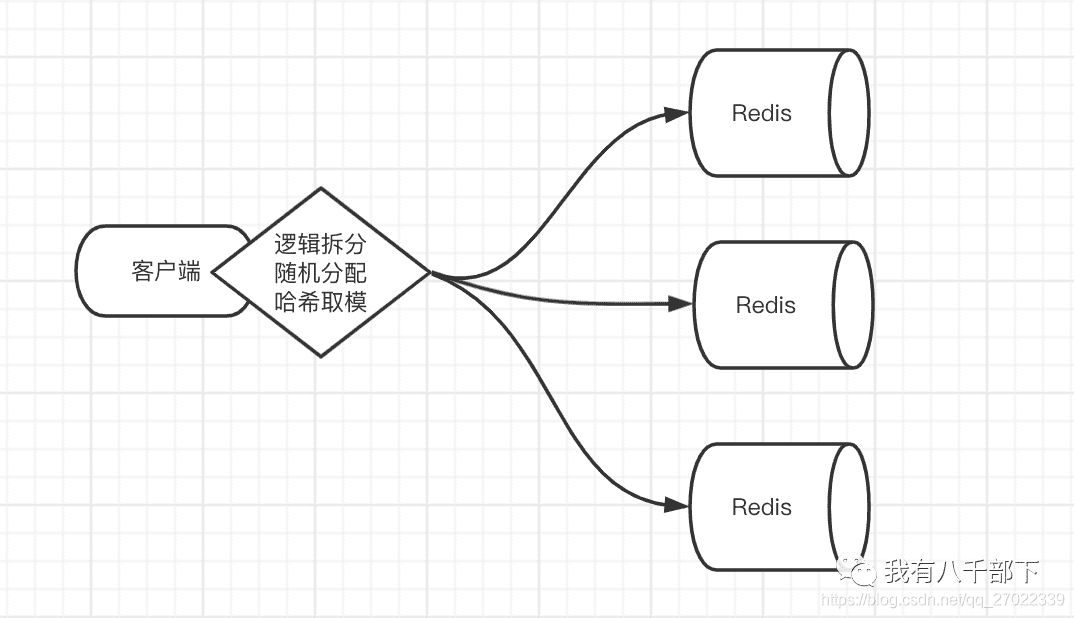
• 逻辑拆分:适用于数据可以进行逻辑分类、交集不多、且一个Redis服务的容量足以支持一类的情况。在实现过程中,数据在逻辑上分配到同一个Redis服务中,例如按业务分类。
• 随机分配:与消息队列的使用场景类似,将数据写入任意Redis服务。每个Redis服务都有消费者来消费数据。一般使用List数据类型PUSH POP等操作。
一致性哈希基于哈希取模方法,解决了动态增删节点不方便的问题。
首先虚拟化2的32次方节点,并将它们视为顺时针方向首尾相连的环。获取你的Redis实体服务的信息,进行哈希运算,然后对虚拟节点的数量取模,映射到环上的虚拟节点,如图中A、C两点所示。
读写数据时,采用同样的方法计算Key作为参数,映射到环上的虚拟节点(如数据A)。如果虚拟节点没有对应Redis实体服务,则顺时针查找最近的实体。该服务完成操作。
当新增节点时,A→C段的原始数据将移交给C。当新增节点B时,A→B段的数据将移交给C B,B→C段的数据将被移交。但这样会带来一个新的问题,一小部分数据无法命中,即原A→B段cache到C的旧数据无法访问,因为访问现在落在B身上,最终导致cache崩溃,访问压力落在数据库上,而且还占用了C的内存。
第一种方案是访问数据时顺时针取两个节点;第二种方式是为缓存的数据设置过期时间,无法访问的数据会从数据库中读取并缓存到新节点,而旧的数据会因过期而被淘汰。
数据倾斜是指数据经过计算映射到同一个段时,会对最近的实体服务造成过大的压力。例如,如果数据映射到区域C→A,那么节点A的访问压力将会非常大。解决方案是将Redis实体服务映射到多点,分散多段映射区域的压力。
客户端执行分片算法后,需要连接到对应的Redis来完成操作,这意味着每个客户端都会连接到每个Redis。当客户端数量增加时,Redis服务的连接开销相对较高。
代理的出现主要是为了解决客户端分片时Redis连接开销过大的问题。客户端只连接代理,代理与后续的Redis服务建立连接。而且,让agent实现分片算法,分片算法是无状态的,只负责计算并路由操作到对应的Redis服务,不存储数据。为了高可用,可以在客户端和代理之间加一层负载均衡,比如LVS + Keepalived。
无论是客户端分片还是代理分片,扩展性和新节点的重新分片都是不可避免的问题;这些方法适合使用Redis作为缓存,但不适合用作数据库,因为用于数据库的数据是不会丢失的。
Redis Cluster 使用预分配来避免这些问题。虽然数据迁移不可避免,但只需要迁移部分数据,从而减少了问题的规模。
Redis Cluster 是无主模型。模 16384 插槽是通过哈希运算计算出来的,允许集群中的所有节点一起共享这些插槽。每个节点都有同一套哈希算法,并保存集群中所有节点与槽位的映射关系。
客户端可以连接到集群中的任意节点进行操作。节点计算后会比较映射关系。如果是自己管理的话,就会自己完成相应的操作。否则,将向客户端返回一个 MOVE 错误,并提供正确的节点地址,从而允许客户端连接到正确的地址来完成操作。
在集群创建时通过操作命令分配槽位,每个节点可以分配一个或多个副本以实现高可用性。添加或删除节点时,可以使用命令迁移部分槽位。
在数据分片的情况下,由于数据分布在不同的节点上,KEYS、MULTI等聚合操作很难实现。 Redis Cluster给出的解决方案是在Key之前添加统一的{tag}格式,例如{tag}key。这样,只会对标签进行哈希处理,使数据落在同一个节点上。其他代理也以类似的方式使用来实现聚合操作。
Redis 代理部署[1]
Redis 集群部署[2]
[1]Redis-代理部署:https://www.sychzs.cn/qq_27022339/article/details/119545441[2]Redis-集群部署:https://www.sychzs.cn/qq_27022339/article/details/119576728
[1]
[2]