1。 Redis主从复制读写分离问题
0 {IMG_0: Ahr0CHM6LY9PBWFNZXMYMYMDE4LMNUYMXVZ3MUY2JSB2CVOTK2LZIWMTGWNY85MDC1OTMJAXTAYNDQWMTMTMTI1ODA5MZYWM i5WBMC =/}
1)数据复制的延迟
当读写分离时,Master会异步将数据复制到slave。如果这被slave阻止,主数据的写入命令就会延迟,导致数据不一致。
解决方案:可以监控slave的偏移值。如果发现某个slave的偏移量有问题,就会将数据读取操作切换到master上。然而,这种监控开销是比较高的。所以关于这个问题,大多数情况下可以不考虑直接使用。
2)读取过期数据
redis在删除过期key时有两种策略,第一种是惰性策略,即只有redis操作这个key时,才发现该key过期的时候,该密钥将被删除。 第二是定期采样一些key进行删除。
关于上面提到的两种过期策略,都会有一个问题,就是如果过期key的数量非常多,而采样速度无法匹配过期key的生成速度,很多过期数据就不会被删除,但是在redis master和slave达成了协议。 slave无法处理数据(即无法删除数据)且客户端没有及时读取过期数据并同步到master删除key,会导致slave读取到过期数据(这个问题在中已经解决) redis3.2版本)。
2。 Redis主从配置不一致
这个问题一般很少见,但如果发生了,就会出现很多奇怪的问题,比如:
1)最大内存配置不一致:这会导致数据丢失。
原因:比如master配置4G,slave配置2G,此时主从复制就可以成功。但是,如果在某个全量复制的过程中,slave在获取master的RDB加载数据时发现自己的2G内存不够了。这时,slave的maxmemory策略就会被触发,数据就会被淘汰。更可怕的是,在高可用集群环境下,如果你把这个slave升级为master,你会发现数据已经丢失了。
2)数据结构优化参数不一致(如hash-max-ziplist-entries):这会导致内存不一致。
原因:比如如果在master上优化了这个参数,但在slave上没有配置,就会导致主从节点内存不一致的奇怪问题。
3。避免完整复制
首先,redis的复制有两种:全量复制和部分复制,全量复制的开销非常高。那么我们来看看如何尽可能避免全量复制。
1)第一次全量复制
当某slave第一次连接master时,难免要进行全量复制,那么如何想办法减少开销呢?
方案一:小主节点,例如将redis划分为2G节点。这样会加快RDB的生成和同步速度,同时也减少了fork子进程的成本(master会fork一个子进程来生成同步所需的RDB文件,而fork需要快速复制内存,如果主节点内存太多大的话,分叉的成本就会高)。
方案二:由于第一次不可避免,所以可以选择在集群低峰时间(凌晨)挂载slave。
2)节点RunID不匹配
例如主节点重启(RunID改变),对于slave来说,会保存之前主节点的RunID。如果此时发现master的RunID发生了变化,那么就会认为来自master的数据可能不安全,会进行全量拷贝。
解决方案:对于这类问题,唯一的办法就是做一些故障转移的方法,比如master故障,选举一个slave晋升master(哨兵或者集群)。
3)复制积压缓冲区不足
全量复制和部分复制一文提到,master生成RDB并同步到slave。 slave加载RDB期间,Master的所有写命令都会被保存到一个复制缓冲队列中(如果主从直连网络抖动,则采用同样的逻辑进行部分复制),slave加载后RDB,他会取offset值,在这个队列中进行判断。如果在这个队列中,那么将这个队列从offset处移动到最后都进行同步。该队列的默认值为1M。并且如果发现offset不在这个队列中,就会生成full copy。
解决方案:增加复制缓冲区rel_backlog_size的配置。默认为 1M。我们可以将其设置得较大,以提高偏移的命中率。对于这个值,可以假设一般的网络故障时间是分钟级别的。然后我们可以根据当前的QPS计算出每分钟可以写入多少字节,然后乘以可能发生故障的分钟数,就得到我们理想的值。
4。避免复制风暴
什么是复制风暴?例如:master重启,master下的所有节点检测到RunID发生变化,导致所有slave节点向master节点做全量复制。虽然redis对这个问题做了优化,即只生成一个RDB文件,但是需要多次传输,成本还是很高的。
1)单主节点复制风暴:主节点重启,多个从节点完全复制
解决方案:更改复制拓扑,如下图:
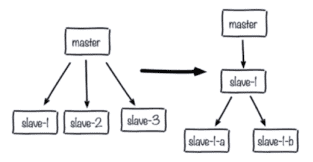
a)在原来的master和slave之间添加一个或多个slaves,然后在slave中添加几个slaves,以分担所有slaves对master复制的压力。 (这个架构还是有问题:读写分离的时候,slave1也失败了,怎么处理?)
b)如果只实现高可用,没有读写分离,那么当master宕机的时候,直接升级成slave就可以了。
2)单机复制风暴:机器宕机后出现大量全量副本,如下图:
2 {IMG_2:Ahr0CHM6LY9PBWFNZXMYMYMDE4LMNUYMXVZ3MUY2JSB2CVOTK2LZIWMTGWNY85MDC1OTMJAXODA3MTAYMTQ4MJK3MTGWNZI2L nbuzw ==/}
当机器-A宕机并重新启动时,会导致该机器所有master下的所有slaves同时被复制。 (灾难)
解决方案:
a)master节点分散在多台机器上(将master分布到不同的机器上部署)
b)并且我们可以采用高可用的方式(slave升master)并且不会出现类似的问题。
==============Redis常见性能问题及解决方案=================
?内存快照。
2)掌握AOF持久化
如果不重写AOF文件,这种持久化方式对性能的影响最小,但是AOF文件会不断增长,过多的AOF文件会影响AOF文件的恢复速度主控重启。
3)Master调用BGREWRITEAOF
Master调用BGREWRITEAOF重写AOF文件。 AOF在重写时会占用大量的CPU和内存资源,导致服务负载过高,服务暂时挂起。
以下是我的一个实际项目的情况。一般情况是这样的:1个Master,4个Slave,没有Sharding机制,只有读写分离。 Master负责写操作和AOF日志备份。 AOF文件大约有5G。 ,Slave负责读操作。当Master调用BGREWRITEAOF时,Master和Slave的负载会突然急剧增加。 Master的写请求基本没有响应,持续5分钟左右。 Slave的读请求也无法及时响应。 Master和Slave的服务器负载图如下:
主服务器负载:

从服务器负载:
4 {IMG_4: Ahr0CHM6LY9PBWFNZXMYMDE4LMNUYMXVZ3MUY2JSB2CVOTK2LZIWMTGWNY85MDC1OTMJAXODA3MTAYMTK2NTKTMTMTMTMTMTMTMTMTMTMTMTMTMTMTMTMTMTMTMTMTMTINNNNNN C5WBMC =/}
上面的情况不会也不应该发生,因为Master机以前是Slave,上面有一个shell定时任务每天上午10点调用BGREWRITEAOF重写AOF文件。后来Master机就宕机了。 ,备份的Slave被切成了Master,但是定时任务却忘记删除了,才导致了上面悲惨的情况。花了好几天才找到原因。
将 no-appendfsync-on-rewrite 配置设置为 yes 可以缓解此问题。设置为yes表示新的写操作在rewrite时不会被fsyncd,会暂时保存在内存中,直到rewrite完成后再进行写入。最好不要启用Master的AOF备份功能。
4)Redis主从复制的性能问题
Slave同步到Master的第一种实现方式是:Slave向Master发送同步请求,Master先dump出rdb文件,然后将整个rdb文件传输给slave ,然后Master将缓存的命令转发给Slave,初始同步完成。第二个及后续的同步实现是:Master将变量的快照实时直接发送给每个Slave。无论什么原因导致Slave和Master断开连接并重新连接,都会重复上述过程。 Redis的主从复制是基于内存快照的持久化。只要有Slave,就会有内存快照。虽然Redis声称主从复制是非阻塞的,但由于Redis使用单线程服务,如果Master快照文件比较大,第一次全量传输会需要很长时间,Master可能无法提供文件传输过程中的服务,也就是说服务会中断,对于关键服务来说,后果也是可怕的。
上述1.2.3.4根本问题的原因都与系统IO瓶颈问题密不可分,即硬盘读写速度不够快,主进程fsync()/write()操作被阻止。
5)单点故障问题
由于目前Redis的主从复制还不够成熟,所以存在明显的单点故障问题。目前,我们只能通过自己的解决方案来解决这个问题,例如:主动复制、Proxy 实现 Slave 配对、Master 的替代等,也是目前的优先任务之一。
简单总结:
-Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,尤其不要启用内存快照进行持久化。
- 如果数据很关键,Slave会启用AOF备份数据,策略是每秒同步一次。
- 为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内。
- 尽量避免在压力较大的主库上添加从库
- 为了Master的稳定性,不要使用图结构进行主从复制。采用单向链表结构比较稳定,即主从关系为:Master<-Slave1<-Slave2<-Slave3……。这种结构也方便解决单点故障问题,实现Slave替代Master。也就是说,如果Master挂了,可以立即启用Slave1作为Master,其他不变。 。






















![msp430f5529单片机简介[msp430f247单片机]](/upload/images/33979569)
