package cn.lsl.dom.jaxp;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.NodeList;
public class DOMTest {
//将 books.xml 加载内存中,将文档内容 写入另一个xml books_bak.xml
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
DOMSource domSource = new DOMSource(document); //用document构造数据源
package cn.lsl.dom.jaxp;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import www.sychzs.cnResult;
import org.junit.Test;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
public class DOMCURDTest {
@Test
public void testAdd() throws Exception{
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = builderFactory.newDocumentBuilder();
Document document = builder.parse("books.xml");
//添加节点,创建节点books
Element newBook = document.createElement("book");
newBook.setAttribute("id", "b003");
//创建name节点
Element newName = document.createElement("name");
newName.setTextContent("编程高手");
//将新name放入新book
newBook.appendChild(newName);
//添加节点到指定位置 ---- 获得books根节点
Element root = document.getDocumentElement();
root.appendChild(newBook);
//回写
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
DOMSource domSource = new DOMSource(document);
StreamResult result = new StreamResult(new File("book_bak.xml"));
transformer.transform(domSource, result);
}
}
XML元素修改:查询到指定元素 1、修改属性 setAttribute 2、修改元素文本内容 setTextContent
package cn.lsl.dom.jaxp;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import www.sychzs.cnResult;
import org.junit.Test;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
public class DOMCURDTest {
@Test
public void testUpdate() throws Exception{
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = builderFactory.newDocumentBuilder();
Document document = builder.parse("books.xml");
NodeList nodelist = document.getElementsByTagName("name");
for(int i=0; i
Element name = (Element)nodelist.item(i);
if(name.getTextContent().equals("javaEE")){
Element price = (Element)name.getNextSibling().getNextSibling();
double money = Double.parseDouble(price.getTextContent());
money = money * 1.2;
price.setTextContent(money + "");
}
}
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
DOMSource domSource = new DOMSource(document);
StreamResult result = new StreamResult(new File("book_bak.xml"));
transformer.transform(domSource, result);
}
}
XML元素删除: 删除节点.getParentNode().removeChild(删除节点)
package cn.lsl.dom.jaxp;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import www.sychzs.cnResult;
import org.junit.Test;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
public class DOMCURDTest {
@Test
public void testDelete() throws Exception{
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = builderFactory.newDocumentBuilder();
Document document = builder.parse("books.xml");
NodeList nodelist = document.getElementsByTagName("name");
for(int i=0; i
Element name = (Element)nodelist.item(i);
if(name.getTextContent().contains("java")){
Element book = (Element)name.getParentNode();
book.getParentNode().removeChild(book);
i--;
}
}
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
DOMSource domSource = new DOMSource(document);
StreamResult result = new StreamResult(new File("book_bak.xml"));
transformer.transform(domSource, result);
}
}
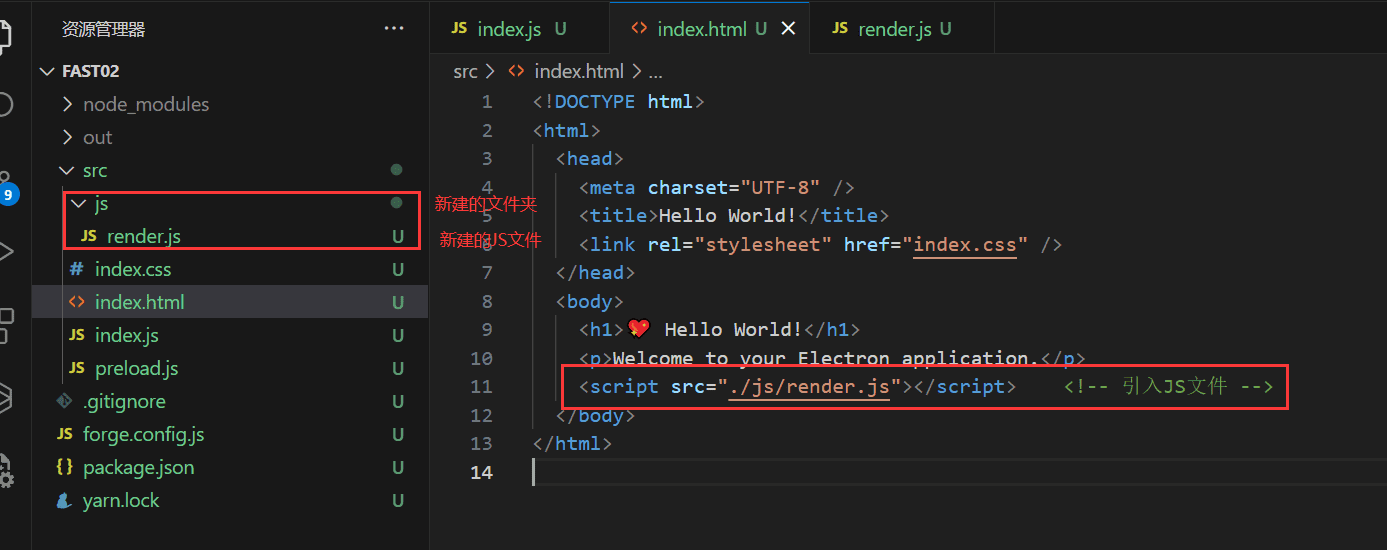
SAX解析
sax解析原理图
在startElement() endElement()获得开始和结束元素名称
在characters()获得读取到文本内容
eg:
UNIX
package cn.lsl.jaxp.sax;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SAXTest {
public static void main(String[] args) throws Exception, Exception {
//1.工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//2.通过工厂获得解析器
SAXParser parser = factory.newSAXParser();
//3.创建Handler
MyHandler handler = new MyHandler();
parser.parse("server.xml", handler);
}
}
class MyHandler extends DefaultHandler{
@Override
public void startDocument() throws SAXException {
System.out.println("start document...");
}
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
System.out.println("start elemnt("+qName+")...");
if(qName.equals("server")){
System.out.println("id属性值:" + attributes.getValue("id"));
}
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
String content = new String(ch, start, length);
System.out.println("character:" + content);
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.println("end element("+ qName +")...");
}
@Override
public void endDocument() throws SAXException {
System.out.println("end document...");
}
}
STAX解析
1.STAX是拉模式的xml解析方式
(为什么是拉模式?)客户端程序,自己控制xml事件,主动调用相应事件方法
2.当使用XML PULL,如果使用Android系统,系统内置无需下载任何开发包,如果想JavaSE JavaEE使用pull解析技术,下载单独pull开发工具包
3.xpp3 --- XML Pull Parser 3 是pull API代码实现
4.使用pull解析器
1)下载pull解析器xpp3(Android内置)
2)将 xpp3-1.1.3.4.C.jar 导入 java工程
3)导入jar包 位于 当前工程内部 , 在工程内新建 lib ,将jar复制过来 , 将pull 解析器 jar 添加build path
5.Pull解析器使用STAX解析方式 --- 拉模式解析
6.Pull采用将xml文档传递解析器,手动通过next触发文档解析事件,在客户端代码中获取当前事件,从而调用相应事件处理方法
7.为什么STAX解析方式效率好于SAX?
1)SAX无选择性的,所有事件都会处理的解析方式,STAX由用户控制需要处理事件类型
2)在使用STAX进行数据解析时,随时终止解析
Pull解析原理
java编程基础
80
java高级应用
100
编程高手秘笈
200
package cn.lsl.pull.stax;
import java.io.FileInputStream;
import org.junit.Test;
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserFactory;
public class PullTest {
//查询 编程高手秘笈的价格
@Test
public void demo2() throws Exception{
XmlPullParserFactory xmlPullParserFactory = XmlPullParserFactory.newInstance();
XmlPullParser parser = xmlPullParserFactory.newPullParser();
parser.setInput(new FileInputStream("books.xml"),"utf-8");
int event;
//定义标志位
boolean isFound = false;
while((event = parser.getEventType())!= XmlPullParser.END_DOCUMENT){
if(event == XmlPullParser.START_TAG && parser.getName().equals("name")){
String bookname = parser.nextText();
if(bookname.equals("编程高手秘笈")){
isFound = true;
}
}
if(event == XmlPullParser.START_TAG && parser.getName().equals("price") && isFound){
System.out.println(parser.nextText());
break;
}
www.sychzs.cn();
}
}
@Test
public void demo1() throws Exception{
//1.工厂
XmlPullParserFactory xmlPullParserFactory = XmlPullParserFactory.newInstance();
//2.通过工厂获得解析器
XmlPullParser parser = xmlPullParserFactory.newPullParser();
//3.将xml文件传递给解析器
parser.setInput(new FileInputStream("books.xml"), "utf-8");
//pull解析器用拉模式解析数据
int event;
while((event = parser.getEventType()) != XmlPullParser.END_DOCUMENT){
if(event == XmlPullParser.START_TAG){
System.out.println(parser.getName() + "元素开始了...");
}
if(event == XmlPullParser.END_TAG){
System.out.println(parser.getName() + "元素结束了...");
}
www.sychzs.cn();
}
}
}
9.Pull解析器生成xml文档功能 --- 通过XmlSerializer生成xml文档
解析xml:文档开始、元素开始、文本元素、元素结束、文档结束
生成xml:生成文档声明(文档开始)、元素开始、文本内容、元素结束、文档结束
三种方式生成xml
1)生成简单xml
2)通过对象数据生成xml
3)通过对象List数据生成xml
eg:
package cn.lsl.domain;
public class Company {
private String name;
private int num;
private String address;
public String getName() {
return name;
}
public void setName(String name) {
www.sychzs.cn = name;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}
package cn.lsl.pull.stax;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.junit.Test;
import org.xmlpull.v1.XmlPullParserException;
import org.xmlpull.v1.XmlPullParserFactory;
import org.xmlpull.v1.XmlSerializer;
import cn.lsl.domain.Company;
public class SerializerTest {
//根据List
生成xml
@Test
public void demo3() throws Exception{
List companies = new ArrayList();
Company company = new Company();
company.setName("软件公司");
company.setNum(200);
company.setAddress("软件园");
Company company2 = new Company();
company2.setName("科技公司");
company2.setNum(1000);
company2.setAddress("软件园");
companies.add(company);
companies.add(company2);
XmlSerializer serializer = XmlPullParserFactory.newInstance().newSerializer();
serializer.setOutput(new FileOutputStream("company.xml"), "utf-8");
serializer.startDocument("utf-8", true);
serializer.startTag(null, "companies");
for(Company c : companies){
serializer.startTag(null, "company");
serializer.startTag(null, "name");
serializer.text(c.getName());
serializer.endTag(null, "name");
serializer.startTag(null, "num");
serializer.text(c.getNum()+"");
serializer.endTag(null, "num");
serializer.startTag(null, "address");
serializer.text(c.getAddress());
serializer.endTag(null, "address");
serializer.endTag(null, "company");
}
serializer.endTag(null, "companies");
serializer.endDocument();
}
//根据company对象数据生成xml
@Test
public void demo2() throws Exception{
Company company = new Company();
company.setName("软件公司");
company.setNum(200);
company.setAddress("软件园");
XmlSerializer serializer = XmlPullParserFactory.newInstance().newSerializer();
serializer.setOutput(new FileOutputStream("company.xml"), "utf-8");
serializer.startDocument("utf-8", true);
serializer.startTag(null, "company");
serializer.startTag(null, "name");
serializer.text(company.getName());
serializer.endTag(null, "name");
serializer.startTag(null, "num");
serializer.text(company.getNum()+"");
serializer.endTag(null, "num");
serializer.startTag(null, "address");
serializer.text(company.getAddress());
serializer.endTag(null, "address");
serializer.endTag(null, "company");
serializer.endDocument();
}
//生成xml
@Test
public void demo1() throws Exception{
//获得XmlSerializer对象
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlSerializer serializer = factory.newSerializer();
//设置序列化输出文档
serializer.setOutput(new FileOutputStream("company.xml"), "utf-8");
//文档开始
serializer.startDocument("utf-8", true);
//元素开始
serializer.startTag(null, "company");
//文本元素
serializer.text("传智播客");
//元素结束
serializer.endTag(null, "company");
//文档结束
serializer.endDocument();
}
}
10.Pull的CURD
对XML数据通过Pull解析器进行CURD原理图
package cn.lsl.pull.stax;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserFactory;
import org.xmlpull.v1.XmlSerializer;
import cn.lsl.domain.Company;
//工具类 抽取两个方法:1、xml -- List 2、List --- XML
public class PullUtils {
//接收xml文件,返回List集合
public static List
parserXml2List(String fileName) throws Exception{
List companies = new ArrayList();
//获得解析器
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
//设置xml输入文件
parser.setInput(new FileInputStream(fileName), "utf-8");
//遍历解析
int event;
Company company = null;
while((event = parser.getEventType())!=XmlPullParser.END_DOCUMENT){
//将每个元素封装Company
//1.在company开始时候,创建对象
if(event == XmlPullParser.START_TAG && parser.getName().equals("company")){
company = new Company();
}
//2.读取name元素时,向company对象中封装name属性
if(event == XmlPullParser.START_TAG && parser.getName().equals("name")){
company.setName(parser.nextText());
}
//3.读取num元素时,想company对象保存num属性
if(event == XmlPullParser.START_TAG && parser.getName().equals("num")){
company.setNum(Integer.parseInt(parser.nextText()));
}
//4.读取address元素,向company封装address属性
if(event == XmlPullParser.START_TAG && parser.getName().equals("address")){
company.setAddress(parser.nextText());
}
//5.读取company元素结束时,将company对象加入集合
if(event == XmlPullParser.END_TAG && parser.getName().equals("company")){
companies.add(company);
}
www.sychzs.cn();
}
return companies;
}
//同时接收xml文件和List集合,将集合中数据写入xml文件
public static void serializeList2Xml(List companies, String fileName) throws Exception{
//获取序列化对象
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlSerializer serializer = factory.newSerializer();
//写文件之前,指定输出文件
serializer.setOutput(new FileOutputStream(fileName), "utf-8");
//文档开始
serializer.startDocument("utf-8", true);
//根元素开始companies
serializer.startTag(null, "companies");
//遍历集合List,每个List中Company对象生成一个片段
for(Company company : companies){
//company开始
serializer.startTag(null, "company");
//name属性开始
serializer.startTag(null, "name");
//写入name数据
serializer.text(company.getName());
//name属性结束
serializer.endTag(null, "name");
//num属性开始
serializer.startTag(null, "num");
//num写入num数据
serializer.text(company.getNum() + "");
//num属性结束
serializer.endTag(null, "num");
//address属性开始
serializer.startTag(null, "address");
//写入address值
serializer.text(company.getAddress());
//address属性结束
serializer.endTag(null, "address");
//company结束
serializer.endTag(null, "company");
}
//根元素结束
serializer.endTag(null, "companies");
//文档结束
serializer.endDocument();
}
}
package cn.lsl.pull.stax;
import java.io.FileInputStream;
import java.util.ArrayList;
import java.util.List;
import org.junit.Test;
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserFactory;
import cn.lsl.domain.Company;
public class PullCURD {
@Test
//将科技公司从列表删除
public void testDelete() throws Exception{
//1.解析xml数据到内存list
List companies = PullUtils.parserXml2List("company.xml");
//2.从list集合中删除科技公司的company对象
for(Company company : companies){
if(company.getName().equals("科技公司")){
companies.remove(company);
break;
//如果没有加break;会发生并发访问异常,,因为foreach循环中不能改变长度,
//改变长度时在下一次判断长度会报异常,
//用break跳出循环,没有下一次判断长度,所以可以避免
}
}
PullUtils.serializeList2Xml(companies, "company_bak.xml");
}
@Test
//将科技公司人数增加200%
public void testUpdate() throws Exception{
//1.解析xml数据到内存list
List companies = PullUtils.parserXml2List("company.xml");
//2.增加科技公司人数200%
for(Company company : companies){
if(company.getName().equals("科技公司")){
company.setNum(company.getNum() * 2);
}
}
PullUtils.serializeList2Xml(companies, "company_bak.xml");
}
@Test
//查询软件公司的人数
public void testSelect() throws Exception{
//1.解析xml数据到内存list
List companies = PullUtils.parserXml2List("company.xml");
//2.遍历集合对象
for(Company company : companies){
if(company.getName().equals("软件公司")){
System.out.println(company.getNum());
}
}
}
@Test
//向company出入一个公司
public void testAdd() throws Exception{
//1.解析xml数据到内存list
List companies = PullUtils.parserXml2List("company.xml");
//2.添加company对象
Company company = new Company();
company.setName("软件科技公司");
company.setNum(5000);
company.setAddress("软件园");
companies.add(company);
PullUtils.serializeList2Xml(companies, "company_bak.xml");
}
//测试工具类PullUtils中方法
@Test
public void demo2() throws Exception{
//将company.xml复制company_bak.xml
//解析获得集合
List companies = PullUtils.parserXml2List("company.xml");
//将集合写入company_bak.xml
PullUtils.serializeList2Xml(companies, "company_bak.xml");
}
//将xml中数据 ---- List集合对象
@Test
public void demo1() throws Exception{
List companies = new ArrayList();
Company company = null;
//获得解析器
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
//向解析器传入xml文档
parser.setInput(new FileInputStream("company.xml"), "utf-8");
//遍历解析
int event;
while((event = parser.getEventType())!=XmlPullParser.END_DOCUMENT){
if(event == XmlPullParser.START_TAG && parser.getName().equals("company")){
company = new Company();
}
if(event == XmlPullParser.START_TAG && parser.getName().equals("name")){
company.setName(parser.nextText());
}
if(event == XmlPullParser.START_TAG && parser.getName().equals("num")){
company.setNum(Integer.parseInt(parser.nextText()));
}
if(event == XmlPullParser.START_TAG && parser.getName().equals("address")){
company.setAddress(parser.nextText());
}
if(event == XmlPullParser.END_TAG && parser.getName().equals("company")){
companies.add(company);
}
www.sychzs.cn();
}
for(Company c : companies){
System.out.println(c.getName());
System.out.println(c.getNum());
System.out.println(c.getAddress());
System.out.println("=========");
}
}
}
-->