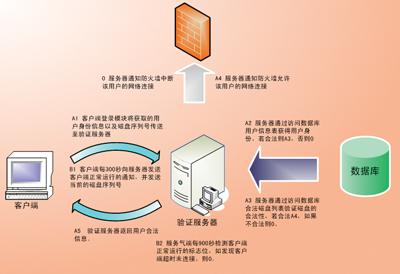
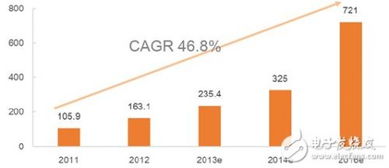
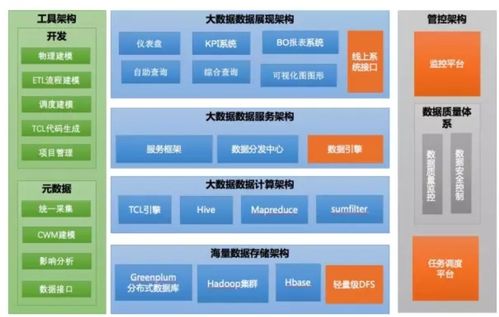
随着网络技术的飞速发展,恶意软件已经成为网络安全领域的重要威胁。恶意软件可以窃取个人信息、破坏系统、传播病毒,对个人和企业安全构成严重威胁。为了有效应对这一威胁,研究人员和安全专家不断探索新的恶意软件检测方法,其中,使用大规模数据集进行训练和测试是提高检测准确率的关键。本文将介绍恶意软件检测数据集的作用以及如何生成恶意软件检测数据集。

恶意软件检测数据集是用于训练和测试恶意软件检测算法的数据集合。它包含了大量已知恶意和良性软件样本,为研究人员提供充足的数据资源,以便训练更加准确的检测模型。通过使用恶意软件检测数据集,研究人员可以评估算法的性能、优化模型参数,提高恶意软件检测的准确性和效率。

生成恶意软件检测数据集需要以下几个步骤:
1. 数据收集:首先需要收集大量的恶意和良性软件样本。这些样本可以从安全厂商、开源社区、公共数据集等渠道获取。收集到的样本需要进行筛选和清洗,去除重复或无效的数据。
2. 标签处理:将收集到的软件样本进行分类和标注。良性软件样本标注为“良性”,恶意软件样本标注为“恶意”。标注过程需要借助专业的安全工具和人工分析。
3. 数据格式化:将收集和标注好的数据进行格式化处理,使其符合机器学习算法的要求。通常需要将数据转换为特定的文件格式(如CSV、JSO等)或者直接转换为二进制格式。
4. 数据扩增:为了提高检测模型的泛化能力,需要对数据进行扩增处理。扩增可以通过旋转、平移、缩放等操作实现,也可以采用更复杂的转换方法,如随机扰动、数据增强等。
5. 数据划分:将数据集划分为训练集、验证集和测试集。训练集用于训练检测模型,验证集用于调整模型参数和选择最佳模型,测试集用于评估模型的性能和泛化能力。
6. 数据匿名化:为了保护个人隐私和商业机密,需要对数据集进行匿名化处理。常见的处理方法包括去标识化、泛化等。经过匿名化处理后的数据集可以更好地保护个人和企业隐私信息。
恶意软件检测数据集是提高网络安全防护能力的重要资源。通过使用大规模的数据集进行训练和测试,可以不断提高恶意软件检测算法的性能和准确率。在生成恶意软件检测数据集时,需要收集大量样本并进行分类标注、格式化处理、扩增划分等步骤。同时,为了保护个人隐私和企业机密,需要对数据进行适当的匿名化处理。未来,随着网络安全威胁的不断变化和发展,我们需要不断更新和完善恶意软件检测数据集,以应对日益复杂的网络安全威胁。