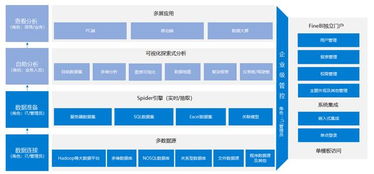
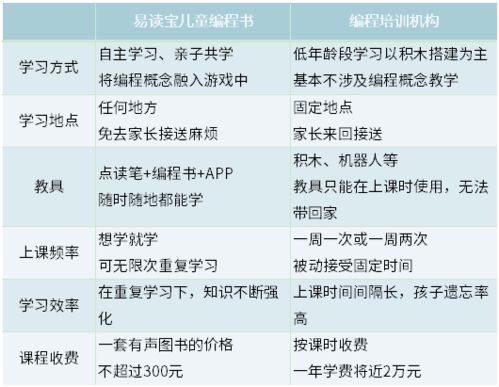
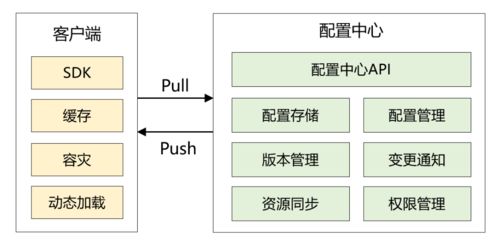
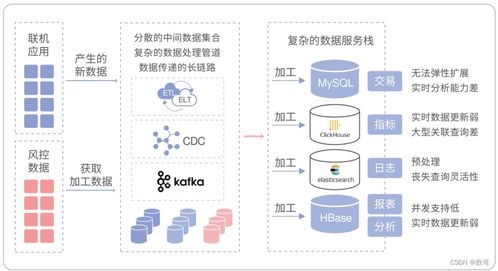
本实验的目标是通过对给定的文本数据集进行深入分析,掌握文本数据处理和分析的基本流程,包括数据清洗、特征提取、模型训练和评估等步骤,并利用所得结果对数据集进行解释和预测。

本次实验使用的数据集是一份关于新闻报道的文本数据,涵盖了多个主题,如政治、经济、社会等。数据集中的每条记录都包含一篇新闻报道的和内容,以及该报道的发布时间、来源等信息。数据集的大小为10000条记录,其中80%用于训练,20%用于测试。

1. 数据清洗:去除无关信息和噪声,如广告、评论等。
2. 文本分词:将文本内容分解成独立的单词或短语。
3. 停用词过滤:去除常见但无实际意义的词汇,如“的”、“和”等。
4. 词干提取:将单词简化为其基本形式,提高特征的泛化能力。
5. 特征选择:基于文本内容提取关键特征,如词频、TF-IDF等。

1. 词频特征:统计每个单词在文本中出现的次数,生成词频矩阵。
2. TF-IDF特征:计算每个单词的重要程度,生成TF-IDF矩阵。
3. -gram特征:将单词组合成-gram,生成-gram矩阵。
4. 主题模型:利用潜在狄利克雷分布(LDA)对文本进行主题建模,生成主题概率分布矩阵。

1. 分类器选择:选择朴素贝叶斯分类器作为基础模型,并尝试集成学习等方法进行优化。
2. 训练过程:使用训练数据对分类器进行训练,生成模型参数。
3. 评估方法:采用准确率、召回率和F1分数等指标对模型进行评估。
4. 参数调优:通过交叉验证等方法对模型参数进行优化,提高模型性能。
1. 结果解释:根据实验结果,分析不同特征和模型对分类性能的影响,并对结果进行解释。
2. 优化建议:根据实验过程中遇到的问题和不足之处,提出优化建议,如增加特征、改进预处理方法、尝试新的分类器等。
1. 本实验通过对文本数据分析技术的实践,掌握了从数据预处理到模型评估的全流程,并取得了一定的成果。在实验过程中,我们发现特征工程和参数调优是影响分类性能的关键因素,未来可以进一步深入研究。
2. 展望:随着深度学习技术的发展,自然语言处理领域取得了重大突破。未来我们可以尝试使用深度学习模型,如卷积神经网络(C)、循环神经网络(R)或长短期记忆网络(LSTM)等,进一步提高文本分类的性能。同时,我们也应该关注文本数据的隐私和安全问题,保护用户隐私和数据安全是我们在使用文本数据分析技术时必须重视的问题。在未来的工作中,我们应该加强这方面的研究和探索。