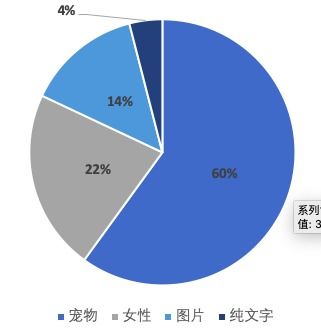
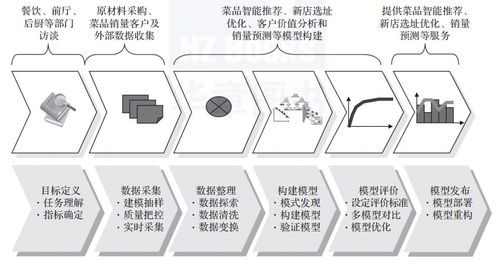
随着大数据时代的到来,文本数据成为了信息传递、知识共享、社交互动等方面的重要载体。为了更好地挖掘文本数据的价值,文本数据分析技术应运而生。本文将对文本数据分析技术的各个方面进行详细介绍,包括文本数据预处理、文本特征提取、文本分类与聚类、情感分析、信息抽取与关系抽取、问答与推荐系统以及文本可视化。

文本数据预处理是文本数据分析的第一步,其主要目的是对原始文本数据进行清洗、分词、去停用词等操作,以提高后续分析的准确性和效率。预处理过程中,需要针对不同的语言和领域特点,选择合适的分词工具和算法,去除文本中的冗余信息,为后续的特征提取和模型训练打下基础。

文本特征提取是文本数据分析的关键步骤,其主要目的是将原始文本数据转化为机器学习算法可以处理的数值型特征。常见的文本特征提取方法包括词袋模型、TF-IDF、word2vec等。这些方法通过对文本中的词语进行统计或语义分析,提取出文本的特征向量,为后续的分类、聚类等任务提供支持。

文本分类是将文本数据按照一定的分类标准进行划分的过程,如新闻分类、情感分类等。常见的分类算法包括逻辑回归、支持向量机、朴素贝叶斯等。聚类是将相似度较高的文本数据划分为同一簇的过程,常用于文档聚类、社区发现等场景。常见的聚类算法包括K-meas、层次聚类等。

情感分析是对文本数据中的情感倾向进行识别和分析的过程,常用于舆情监控、产品评论分析等领域。情感分析方法可分为基于规则和基于机器学习两种。基于规则的方法通过预设规则对文本进行情感判断;基于机器学习的方法则通过训练模型对文本进行情感分类。常用的情感分析算法包括朴素贝叶斯、支持向量机等。

信息抽取是从文本数据中提取出关键信息的过程,如人名、地名、时间等。信息抽取常用于知识图谱构建、问答系统等领域。常用的信息抽取方法包括规则匹配和命名实体识别等。关系抽取是从文本数据中识别实体间关系的过程,如人物关系抽取、事件关系抽取等。关系抽取常用于社交网络分析、事件驱动分析等领域。常用的关系抽取方法包括模板匹配和图算法等。

问答系统是根据用户提出的问题,从大量文本数据中寻找答案并返回给用户的过程。常用的问答系统方法包括基于规则的方法和基于机器学习的方法。推荐系统是根据用户的历史行为和兴趣偏好,为用户推荐相关内容的过程。常用的推荐系统方法包括协同过滤和深度学习等。

文本可视化是将文本数据以图形化方式呈现的过程,以便用户更好地理解和分析数据。常见的文本可视化技术包括词云图、主题模型可视化、知识图谱可视化等。这些技术可以帮助用户直观地了解文本数据的主题分布、关键词频率等信息,为后续的数据分析和决策提供支持。
本文介绍了文本数据分析技术的各个方面,包括文本数据预处理、文本特征提取、文本分类与聚类、情感分析、信息抽取与关系抽取、问答与推荐系统以及文本可视化等。这些技术在实际应用中有着广泛的应用前景,能够帮助我们从海量文本数据中挖掘出有价值的信息和知识,为各个领域的发展提供有力支持。