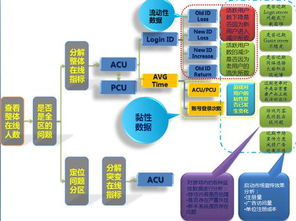
1. 引言
随着大数据时代的到来,多维数据分析技术在各个领域得到了广泛应用。本实验报告旨在介绍多维数据分析实验的过程、方法和结果,为相关领域的研究和实践提供参考。
1.1 实验目的
本实验旨在通过多维数据分析方法,对数据进行深入挖掘和分析,发现数据中的规律和趋势,为决策提供支持。
1.2 实验背景
多维数据分析技术广泛应用于商业智能、风险管理、客户关系管理等领域。通过对多个维度的数据进行综合分析,可以更全面地了解数据的特征和规律,为决策提供更准确、更全面的支持。
2. 数据预处理
在多维数据分析之前,需要对数据进行预处理,包括数据清洗、转换和离散化等步骤。
2.1 数据清洗
数据清洗的目的是去除数据中的异常值、缺失值和不相关数据,提高数据的质量和可靠性。本实验中,我们采用了多种数据清洗方法,如删除重复数据、填充缺失值、平滑异常值等。
2.2 数据转换
数据转换的目的是将原始数据转换为适合多维数据分析的形式。本实验中,我们采用了多种数据转换方法,如数据标准化、数据归一化、数据编码等。
2.3 数据离散化
数据离散化的目的是将连续型数据转换为离散型数据,以便于进行多维数据分析。本实验中,我们采用了多种数据离散化方法,如分箱、WOE转换等。
3. 多维数据分析方法
多维数据分析方法包括描述性统计、聚类分析、关联规则挖掘和序列模式挖掘等。
3.1 描述性统计
描述性统计是通过计算各种统计量(如均值、方差、标准差等)来描述数据的分布特征和规律。本实验中,我们对多个维度的数据进行描述性统计分析和比较。
3.2 聚类分析
聚类分析是将数据按照某种相似性度量方法分为多个簇的过程。本实验中,我们采用了K-meas聚类算法对数据进行聚类分析,并对聚类结果进行讨论和解释。
3.3 关联规则挖掘
关联规则挖掘是发现数据集中变量之间的有趣关系(如关联规则、序列模式等)的过程。本实验中,我们采用了Apriori算法进行关联规则挖掘,并找出了一些有趣的关联规则。
3.4 序列模式挖掘
序列模式挖掘是发现数据集中事件之间的有趣序列关系的过程。本实验中,我们采用了SPADE算法进行序列模式挖掘,并找出了一些有趣的序列模式。
4. 实验结果与讨论
4.1 结果展示
本实验中,我们得到了多个维度的描述性统计结果、聚类结果、关联规则和序列模式。这些结果展示了数据的分布特征、相似性以及变量之间的有趣关系。
4.2 结果讨论
通过对结果的讨论和分析,我们发现了一些有趣的规律和趋势。例如,在聚类分析中,某些簇具有相似的特征和行为;在关联规则挖掘中,某些变量之间存在较强的关联关系;在序列模式挖掘中,某些事件之间的序列关系具有一定的规律性。这些规律和趋势可以为企业决策提供重要的参考和支持。
5. 结论与展望
通过本次多维数据分析实验,我们得到了丰富的结果和深入的见解。这些结果不仅展示了数据的分布特征和规律,还揭示了变量之间的有趣关系和趋势。这些见解可以为企业的决策提供重要的支持和参考。未来,我们将继续深入研究多维数据分析技术,探索更多的应用场景和潜力,为企业的发展和创新做出更大的贡献。