
机器学习已经逐渐渗透到我们的日常生活和工作中,从智能手机到医疗诊断,从个性化推荐到自动驾驶汽车。为了充分利用机器学习的潜力,我们首先需要一个高质量的数据集。本文将详细介绍从数据预处理到应用的全过程,包括数据清洗、集成、变换、规约、特征工程、模型训练与评估以及数据安全与隐私保护等方面。

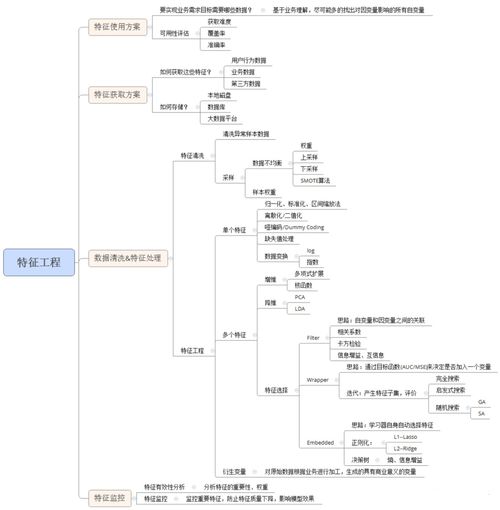
1. 数据清洗:通过删除重复、无效或异常值,纠正错误,以及填充缺失值,确保数据的准确性和一致性。
2. 数据集成:将来自不同来源的数据进行合并,形成单一的数据集,以便后续处理和分析。
3. 数据变换:通过缩放、归一化、标准化等操作,将数据转换为适合机器学习算法的形式。
4. 数据规约:通过选择重要特征、降低维度等方法,减少数据的复杂性,提高计算效率和模型性能。

1. 数值型特征:对原始数据进行计算和转换,生成新的数值特征,如平方、对数等。
2. 类别型特征:将文本、图像等非数值特征转换为数值形式,如独热编码(Oe-Ho Ecodig)。
3. 时间序列特征:针对时间序列数据,提取周期性、趋势性等特征,如移动平均值、傅里叶变换等。
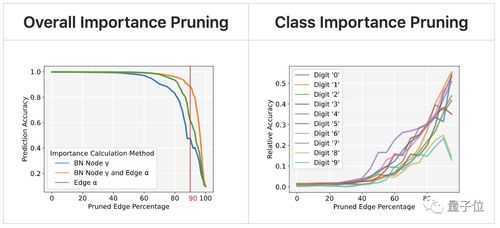
4. 特征选择与降维:通过相关性分析、特征重要性评估等方法,选择关键特征,降低数据维度,提高模型性能。

1. 模型选择:根据问题类型和数据特点,选择合适的机器学习算法和模型。
2. 训练与验证:使用部分数据作为训练集,剩余数据作为验证集或测试集,进行模型训练和验证。
3. 评估指标:根据具体问题选择合适的评估指标,如准确率、召回率、F1分数等,以评估模型的性能。

通过调整模型的参数或尝试不同的优化方法(如网格搜索、随机搜索等),以寻找最佳的模型配置,提高模型的性能和泛化能力。

在机器学习应用中,数据的安全性和隐私保护至关重要。应采取适当的措施来保护数据免受未经授权的访问和使用,例如加密技术、访问控制和匿名化处理等。还需要遵循相关的数据保护法规和政策,以确保合法合规地进行数据处理和使用。

随着技术的不断发展,机器学习在各个领域的应用也越来越广泛。例如,在医疗领域中,可以利用机器学习算法进行疾病诊断和治疗方案优化;在金融领域中,可以利用机器学习算法进行风险评估和投资策略优化;在交通领域中,可以利用机器学习算法进行交通流量预测和智能驾驶等。未来,随着大数据、云计算和人工智能技术的不断发展,机器学习将会在更多领域得到应用和发展。同时,随着算法和技术的不断创新和改进,机器学习的性能和泛化能力也将不断提升。