
该数据集是由一位知名的互联网公司开发的,它主要包括了互联网上的各种文本信息,比如新闻报道、社交媒体上的帖子、论坛讨论、博客文章等等。该数据集的开发者采用了多种方法来收集这些文本信息,包括爬虫程序、API接口以及人工收集等等。该数据集的内容涵盖了多个领域,包括政治、经济、文化、科技等等,具有广泛的应用价值。

该数据集的数据类型主要包括文本信息和标签信息。文本信息是指文章的内容,标签信息是指对文章进行分类的标签。该数据集的维度较高,包含了大量的文本信息,因此需要进行有效的特征提取和选择。数据的分布情况呈现出一定的不平衡性,一些类别的样本数量较多,而另一些则较少。这需要我们在训练模型时进行一定的处理,例如采用过采样、欠采样等方法。数据的可用性和可靠性都比较高,可以用于各种文本分析任务。

在进行文本分析之前,需要对数据进行预处理,包括数据清洗、数据转换、数据缩放以及数据标准化等。数据清洗主要是去除一些无效的数据,例如空值、缺失值等。数据转换主要是将文本信息转化为计算机能够处理的格式,例如将文本信息转化为向量形式。数据缩放主要是将数据的尺度进行调整,使其在同一量级上。数据标准化主要是将数据的均值和标准差进行调整,使其符合标准正态分布。通过这些步骤,将原始数据处理为可用的数据。

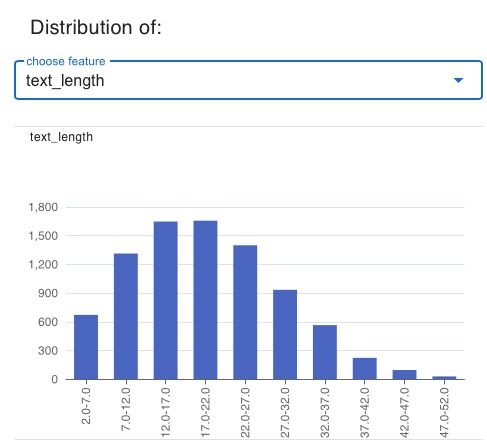
通过图表等形式展示数据集的重要信息,有助于理解数据集的结构和规律。例如,可以通过词云图来展示文本信息中词汇的分布情况,可以通过箱线图来展示数据的分布情况等等。通过可视化技术,可以将数据集中的重要信息呈现出来,帮助我们更好地理解数据集的特征和规律,从而更好地进行文本分析任务。
该文本分析数据集是一个具有广泛应用价值的数据集,它涵盖了多个领域的信息,可以进行各种文本分析任务。在进行文本分析之前,需要对数据进行预处理,并进行可视化分析以更好地理解数据集的特征和规律。通过这些步骤,我们可以更好地进行文本分析任务,提取出有用的信息,为我们的决策提供有力的支持。