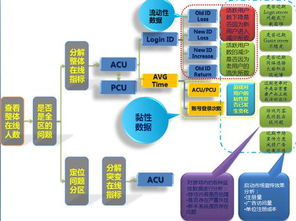
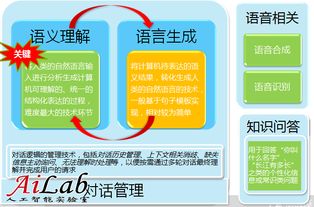
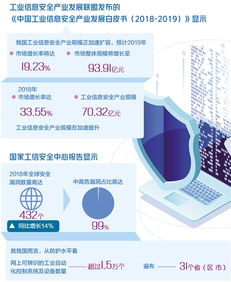
1. 引言
随着信息技术的快速发展,我们面临着海量数据的处理问题。这些数据来源于各种不同的领域,如社交媒体、新闻网站、电商网站等等。如何从这些数据中提取有用的信息,并将其转化为具有价值的文本信息,是当前的一个重要问题。
机器学习是一种通过让机器从数据中学习规律和模式,从而完成特定任务的方法。在自然语言处理领域,机器学习被广泛应用于文本分类、情感分析、自动摘要、机器翻译等任务。本文将介绍如何使用机器学习处理数据生成文章。
2. 数据收集

数据来源:我们需要从哪些网站、数据库或其他来源收集数据? 数据类型:我们需要收集哪些类型的数据?例如文本、图片、视频等? 数据量:我们需要收集多少数据?数据的数量和质量对模型的效果有何影响? 数据标签:如果我们需要对数据进行分类或标注,那么我们需要收集哪些标签?
在收集数据时,我们还需要注意数据的版权和隐私保护问题。
3. 数据清洗
收集到的数据往往包含许多噪声和无关信息,例如重复数据、错误数据、缺失值等等。因此,我们需要进行数据清洗,以去除噪声和无关信息,提高数据的质量和准确性。数据清洗主要包括以下几个方面:
去除重复数据:检查数据中是否有重复的记录或数据,并删除重复的数据。 处理缺失值:检查数据中是否有缺失的值,并采取适当的措施进行处理。例如使用平均值、中位数或其他统计方法填充缺失的值。 去除噪声和异常值:检查数据中是否存在噪声和异常值,并采取适当的措施进行处理。例如使用滤波器或统计方法去除噪声和异常值。 转换数据格式:将数据转换为统一的格式,以便后续处理和分析。例如将文本转换为小写字母、将日期转换为标准格式等等。
4. 数据预处理
在清洗完数据后,我们需要进行数据预处理,以提高模型的学习效果。数据预处理主要包括以下几个方面:
文本预处理:对文本数据进行分词、去除停用词、词干提取等操作,以便模型能够更好地理解文本内容。 特征提取:从数据中提取有用的特征,以便模型能够更好地表示数据。例如使用词袋模型或 TF-IDF 算法提取文本特征。 归一化处理:将特征值缩放到一个统一的范围,以提高模型的准确性和稳定性。例如使用最小-最大归一化将特征值缩放到 [0,1] 范围内。
5. 特征工程
特征工程是指从原始数据中提取有用的特征,并将其输入到机器学习模型中。在文本数据处理中,特征工程主要包括以下几个方面:
词袋模型(Bag of Words):将文本表示为一个词频矩阵,每个单词被表示为一个特征,出现次数即为特征值。这种方法忽略了单词的顺序信息。 TF-IDF(Term Frequecy-Iverse Docume Frequecy):在词袋模型的基础上,加上了单词出现频率的倒数。这种方法可以反映出单词在不同文档中的重要程度。 词嵌入(Word Embeddig):将单词表示为实数向量,利用上下文信息学习单词的语义。这种方法可以捕捉到单词之间的语义关系。 -gram:将文本表示为一个元组频率矩阵,每个元组被表示为一个特征,出现次数即为特征值。这种方法可以捕捉到单词之间的顺序信息。
6. 模型选择与训练
在特征工程之后,我们需要选择一个合适的机器学习模型进行训练,以生成文章。常见的机器学习模型包括逻辑回归、朴素贝叶斯、支持向量机、决策树、随机森林等等。在选择模型时,我们需要考虑以下因素:
数据类型:不同类型的模型适用于不同类型的文本数据。例如,朴素贝叶斯和决策树适用于文本分类任务,而神经网络则适用于情感分析等任务。 数据量:如果我们的数据量较大,那么我们可以选择一些需要大量数据的模型,如随机森林或神经网络。如果我们的数据量较小,那么我们可以选择一些需要较少数据的模型,如逻辑回归或朴素贝叶斯。