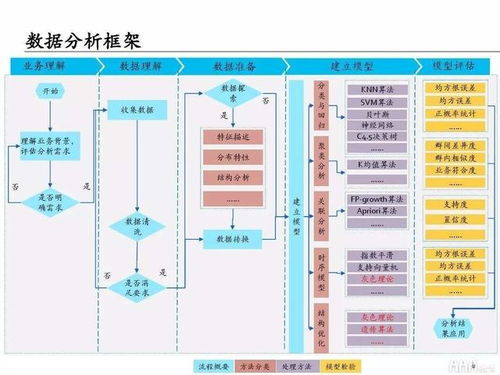

在进行机器学习之前,我们需要收集相关的数据。这些数据可以来自不同的渠道,比如传感器、数据库、API接口等等。收集数据的过程中需要注意数据的真实性、准确性和完整性,以保证后续机器学习算法的可靠性。

收集到的数据往往存在重复、缺失、异常值等问题,需要进行数据清洗。数据清洗主要包括去除重复数据、填补缺失值、消除噪声和异常值等操作。在进行数据清洗的过程中需要关注数据的分布和特征,以避免对数据进行过度处理或误处理。

数据预处理是指将原始数据转换成可用于机器学习的格式。通常需要进行数据归一化、编码转换、特征选择等操作。在进行数据预处理的过程中需要选择合适的算法和技术,以提高数据的处理效率和准确性。

为了更好地应用机器学习算法,我们需要将数据进行转换。数据转换主要包括特征提取、降维等操作。通过数据转换可以减少数据的维度,提高算法的效率,同时也可以挖掘出更有用的特征,提高算法的准确性。

特征工程是指通过提取、构造和选择特征来提高机器学习算法的性能。特征工程的好坏直接影响到机器学习算法的性能。在进行特征工程时需要考虑数据的分布和特征之间的关系,同时还需要了解算法的需求,以构造出更有效的特征。

在完成数据预处理和特征工程后,我们可以使用相应的机器学习算法对数据进行训练和评估。通常我们选择一部分数据作为训练集,另一部分数据作为测试集来评估模型的性能。通过调整模型参数和选择合适的算法,我们可以得到性能更优的模型。

得到的模型可能不是最优的,可能需要进行进一步的优化和调整。常见的优化方法包括正则化、集成学习、超参数搜索等等。通过模型优化和调整可以提高模型的准确性和鲁棒性,同时也可以提高模型的泛化能力,避免过拟合现象的发生。