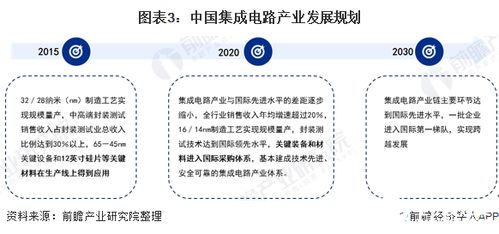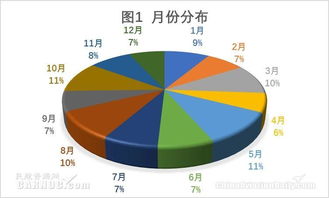
随着数字化时代的到来,文本数据已经成为企业、研究人员以及政策制定者的重要信息来源。文本数据分析技术,即利用计算机科学和人工智能领域的工具和技术,对文本数据进行处理、分析和解释,以提取有价值的信息和洞见。这项技术主要包含以下五个关键步骤:数据预处理、特征提取、模型构建、预测与分析以及可视化呈现。
1. 数据预处理
数据预处理是文本数据分析的第一步,其目标是将原始文本数据进行清洗、整理和标准化,以便后续的分析和处理。这个过程主要包括去除重复数据、分词、词干提取、词形还原以及命名实体识别等任务。
2. 特征提取
特征提取是从预处理后的文本数据中提取出有代表性的特征,用于训练机器学习模型。这些特征可以是基于词袋模型的词频特征,也可以是基于 TF-IDF 模型的权重特征,或者是通过深度学习模型(如词嵌入、卷积神经网络或循环神经网络)提取的语义特征。
3. 模型构建
模型构建是利用机器学习或深度学习算法构建预测模型的过程。常见的机器学习算法包括朴素贝叶斯、支持向量机、逻辑回归等。而深度学习模型如卷积神经网络(C)、循环神经网络(R)、长短期记忆网络(LSTM)和 Trasformer 等则更适合处理复杂的文本数据。
4. 预测与分析
预测与分析阶段主要是利用训练好的模型对新的文本数据进行预测,同时结合分析方法对预测结果进行解释和解读。常见的预测任务包括情感分析、主题分类、实体关系抽取等。而分析方法则可以包括关键词分析、主题模型、语义网络分析等。
5. 可视化呈现
可视化呈现是将分析结果以直观的方式呈现给用户,帮助他们更好地理解和解读数据。常见的可视化方式包括词云图、柱状图、折线图、热力图等。通过这些可视化工具,用户可以更直观地了解文本数据的主题分布、情感倾向以及关键信息等。
文本数据分析技术为我们提供了一种有效的方法来处理和理解大量的文本数据。通过合理的预处理、特征提取、模型构建、预测与分析以及可视化呈现,我们可以从文本数据中提取出有价值的信息和洞见,从而更好地指导决策和行动。