|
问候,
我遇到了以下问题:
给定一个具有以下结构的文件:
\'>some cookies
chocolatejelly
peanutbuttermacadamia
doublecoconutapple
\'>some icecream
cherryvanillaamaretto
peanuthaselnuttiramisu
bananacoffee
\'>some other stuff
letsseewhatfancythings
wegotinhere
目的:将所有包含\'> \'的行之后的所有条目作为单个字符串放入列表中
码:
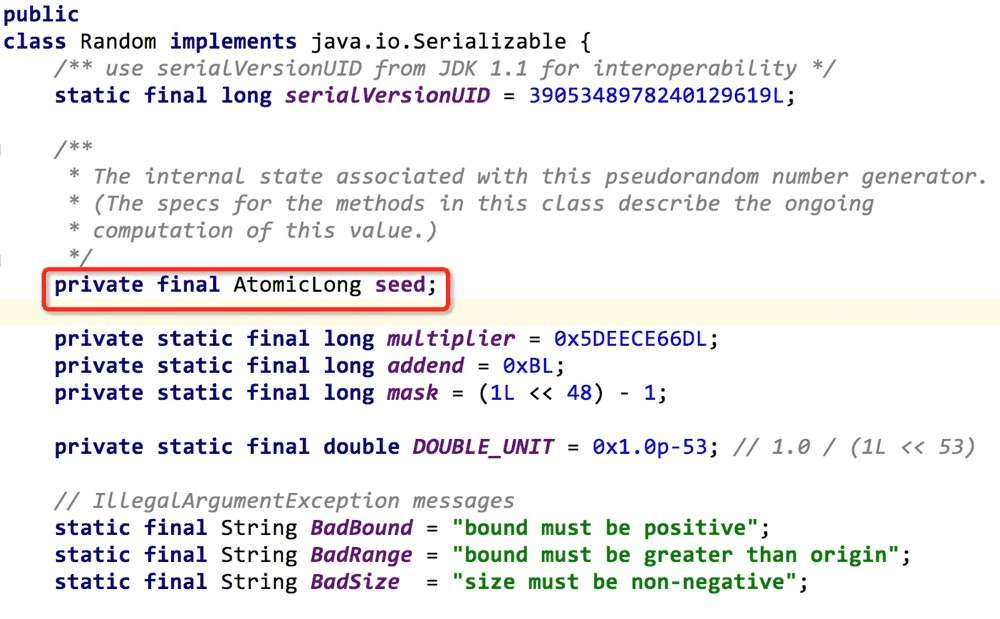
def parseSequenceIntoDictionary(filename):
lis=[]
seq=\'\'
with open(filename, \'r\') as fp:
for line in fp:
if(\'>\' not in line):
seq+=line.rstrip()
elif(\'>\' in line):
lis.append(seq)
seq=\'\'
lis.remove(\'\')
return lis
因此,此功能遍历文件的每一行
如果没有出现\'> \',则将所有以下行连接起来并删除
然后\',
如果出现\'> \',它会自动将连接的字符串附加到列表中,并将\'sclear \'字符串\'seq \'附加到列表中以连接下一个序列
问题:
以输入文件为例,它只将“一些cookie”和“一些冰淇淋”中的内容放入列表中,而不是“其他”中的内容。因此,我们得到:
[chocolatejelly
peanutbuttermacadamia
doublecoconutapple, cherryvanillaamaretto
peanuthaselnuttiramisu
bananacoffee] but not
[chocolatejelly
peanutbuttermacadamia
doublecoconutapple, cherryvanillaamaretto
peanuthaselnuttiramisu
bananacoffee, letsseewhatfancythings
wegotinhere]
这里有什么错误的想法?我可能没有注意过迭代中的一些逻辑错误,但是我不知道在哪里。
预先感谢您的任何提示!










![[转]Windows10中Virtualbox没办法选择和安装64位的Linux系统](/upload/images/374622)



![[ThinkPHP] 环境变量](/upload/images/18909504)


