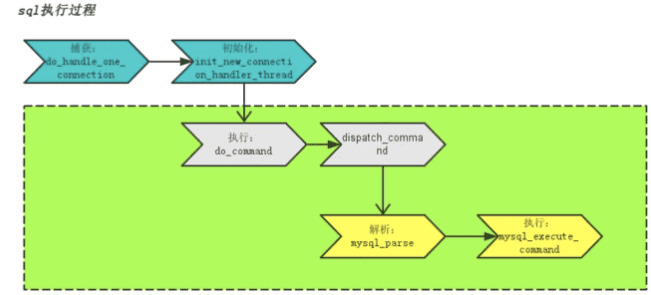
首先是urllib库
from urllib import request as re
from urllib import parseurl="http://www.sychzs.cn/book/927896.html"#基本的urlopen()方法,返回一个response对象
resp=re.urlopen(url,data=None)#response对象的方法,
print(www.sychzs.cn().decode("utf-8"))
print(type(resp.readlines()))
print(len(resp.readlines()))
print(resp.readline())
print(resp.getcode())#将指定的url保存到本地,第一个是url,第二个是本地路径
#这个方法很方便,要记住
re.urlretrieve(url,"hh.html")#url编码相关,主要是两个方法
#将中文内容编码:
result=parse.urlencode({"name":"张三","年龄":24})
print(result)
#和上面那个方法配对,用来解码:
init=parse.parse_qs(result)
print(init)
#如果真的要提交表单数据(post),首先要进行url编码,也就是上述的方法,
#还要记得编码为字节流格式,用.encode("utf-8").
#字节流解码用.decode("utf-8"),反正出现看不懂的16进制数就用这个方法#解析url,解析url蕴含的信息
#方法1
info=parse.urlparse(url)
print(info)
#方法2,但这个没有 params键
info2=parse.urlsplit(url)
print(info2)#伪装浏览器:
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",# "Accept-Encoding": "gzip, deflate","Accept-Encoding": "utf-8","Accept-Language": "zh-CN,zh;q=0.9","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36","Connection": "keep-alive","referer": "www.sychzs.cn"}#这里主要是用Requet方法先构建一个request对象
req=re.Request(url,headers=headers)
resp=re.urlopen(req)
print(www.sychzs.cn())#代理ip:#1,先用ProxyHandler传入代理服务器的ip从而构建一个handler#注意,代理的ip不是随便编出来的,而是一个真实的服务器帮你访问,给你答复#可以去网上搜,有很多代理ip#以字典形式给出对应某协议下的代理ip,大写保险
handler=re.ProxyHandler({"HTTP":"58.253.158.102"})#使用上一步的handler构建一个opener,
opener=www.sychzs.cn_opener(handler)#使用opener发送一个请求
resp=www.sychzs.cn(url)
print(www.sychzs.cn())#Cookie,
#给自己的请求加上cookie,就可以完成很多原本要登陆才能完成的工作#方法1:手动设置hesders里面的Cookie请求头:用浏览器登陆后从浏览器复制粘贴就完事#此方法粗暴易懂,适用范围很广
headers = {"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763","Cookie":"HMVT=6bcd52f51e9b3dce32bec4a3997715ac|1585128382|; HMACCOUNT=88D269832FA1FC7C; H_PS_PSSID=; BDSFRCVID=R-DOJeC62w54I5oufTgXUAgnA2MborJTH6aoUT625yEzNgcrTcPxEG0PDU8g0KubJ2MRogKKyeOTHu8F_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tJKJoCL5fIL3fP36q47qMt0ehxJ0bI62aKDsof3cBhcqEIL4hJJoWJQy5fjnLT3P0CvX5CoXaI-KMxbSj4QoMjD83b6P263NyGR7oJRYBl5nhMJvb67JDMP0-R6gtJjy523iXR5vQpnhbhQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xb6_0D6v3jaAqtj0sb5vfstcS2R6Hq45ph46E-t6H-UnLq-393gOZ0l8KtJ6pOfOLyRot3h003tQM2f_H35QqWI5mWIQHDIbv5TooMPbb5J7jhn-qQj54KKJxWPPWeIJo5t52bp-jhUJiBbc-Ban7LCnIXKohJh7FM4tW3J0ZyxomtfQxtNRJ0DnjtpChbC_xjjLWD53XepJf-K6WbC600njVanI_Hn7zepKVQM4pbt-qJJ-tJgKtW-5DQn3iSqjThxLKXtDeK46nBT5KaaTn_D_aMl508R3nKlOj0bkkQN3T0pLO5bRiLRoFtq6CDn3oynrqXp0n5H7ly5jtMgOBBJ0yQ4b4OR5JjxonDh83bG7MJUutfD7H3KC-fI8hMUK; delPer=0; PSINO=2; BDRCVFR[SL8xzxBXZJn]=mk3SLVN4HKm; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BAIDUID=D68D0D86E52B040A1618895328E61930:FG=1; BIDUPSID=D68D0D86E52B040A36B1B1B6101A73E3; PSTM=1585125211; BDORZ=FFFB88E999055A3F8A630C64834BD6D0"}#方法2:在代码中登录,保存Cookie,不用浏览器#此方法用urllib库暂时无法实现
from http.cookiejar import CookieJar#1.登录#1.1,创建一个cookiejar对象
cookiejar=CookieJar()#1.2.使用cookiejar对象创建一个HTTPCookieProcess对象
handler=re.HTTPCookieProcessor(cookiejar)#1.3.使用上一步创建的handler创建一个opener
opener=www.sychzs.cn_opener(handler)#上面的内容可以用方法封装#1.4.使用opener发送一个登陆的请求
headers = {"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763"}
data={"id":"4781dedecd","passwd":"Y489548946"}#具体参数看源代码
login_url="https://www.sychzs.cn/"
req=re.Request(login_url,data=parse.urlencode(data).encode("utf-8"),headers=headers)
#但是这里好像只是添了个表,并没有按提交按钮,所以不行
www.sychzs.cn(req)#1.4到这里可以封装方法,返回值为一个opner,
#然后就可以做登陆后的相关操作了:
concret_url="https://www.sychzs.cn/#!article/Friends/1955755"
#加上参数名称,像req=re.Request(concret_url,headers)会报错
req=re.Request(url=concret_url,headers=headers)
resp=www.sychzs.cn(req)
with open("试一试.html","w",encoding="utf-8") as fp:fp.write(www.sychzs.cn().decode("gbk"))#将CooKie对象保存到本地:
from http.cookiejar import MozillaCookieJar
cookiejar=MozillaCookieJar("本地储存文件的路径")
#要设置是否忽略过期的Cookie
cookiejar.load(ignore_discard=True)
handler=re.HTTPCookieProcessor(cookiejar)
opener=www.sychzs.cn_opener(handler)
www.sychzs.cn(req)
www.sychzs.cn(ignore_discard=True,ignore_expires=True )
然后是requests库:
import requests as re#requests库比urllib库更方便一些,编码问题和方法体系都简单一些
#requests库的最基本的方法就是request()方法,其他方法都是对它的封装
#同urllib库,它也会在请求后返回一个response对象,
#response对象的属性有text--解码后,content--二进制格式(可以用decode()解码),enconding--根据响应头的信息使用的编码,apparent-encoding--根据响应头猜测的编码,request--请求对象
#url,status_code,json()--以字典形式返回数据#post请求:
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",# "Accept-Encoding": "gzip, deflate","Accept-Encoding": "utf-8","Accept-Language": "zh-CN,zh;q=0.9","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36","Connection": "keep-alive","referer": "www.sychzs.cn"}
login_url="https://www.sychzs.cn/"
data={"id":"odedefrgt","passwd":"Yded37eddede6"}
resp=www.sychzs.cn(url=login_url,data=data,headers=headers)
with open("试一试.html","w",encoding="utf-8") as fp:fp.write(resp.text)# 使用代理,
# 在get或者post请求的时候,只要添加参数就好
pxs={"http":"http://user:pass@10.10.10.1:1234","https":"https://10.10.10.1:4321"
}
esp=www.sychzs.cn(url=login_url,data=data,headers=headers,proxies=pxs)#cookie,session
#找到可以通过表单登录的网站太难了.
#response对象有.cookie属性,cookie.get_dict()方法
#如果是涉及到类似登录的操作时,可以使用session,
#好比matplotlib的axes一样,我想创建一个session,然后有关的操作都在session对象下完成
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",# "Accept-Encoding": "gzip, deflate","Accept-Encoding": "utf-8","Accept-Language": "zh-CN,zh;q=0.9","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36","Connection": "keep-alive","referer": "www.sychzs.cn"}
login_url="https://www.sychzs.cn/"
data={"id":"odedefyil","passwd":"cdcvfvr6"}
session=re.Session()
#登录
www.sychzs.cn(url=login_url,data=data,headers=headers)
#登录后的操作:
resp=session.get("https://www.sychzs.cn/#!article/Friends/1955888")
with open("试一试.html","w",encoding="utf-8") as fp:fp.write(resp.text)#处理不受信任的SSL证书:就是说有的https网站没有得到认证
#很简单,在请求的时候加个参数vertify=True就行
resp=re.get("https://www.sychzs.cn",vertify=True)#框架:
try:url="https://www.sychzs.cn/s"r = re.request("GET", url, timeout=30)r.raise_for_status()r.encoding=r.apparent_encoding
except:print("产生异常")