大家好,我叫阿轩。
今天我们来分析一下ThreadLocal的源码。
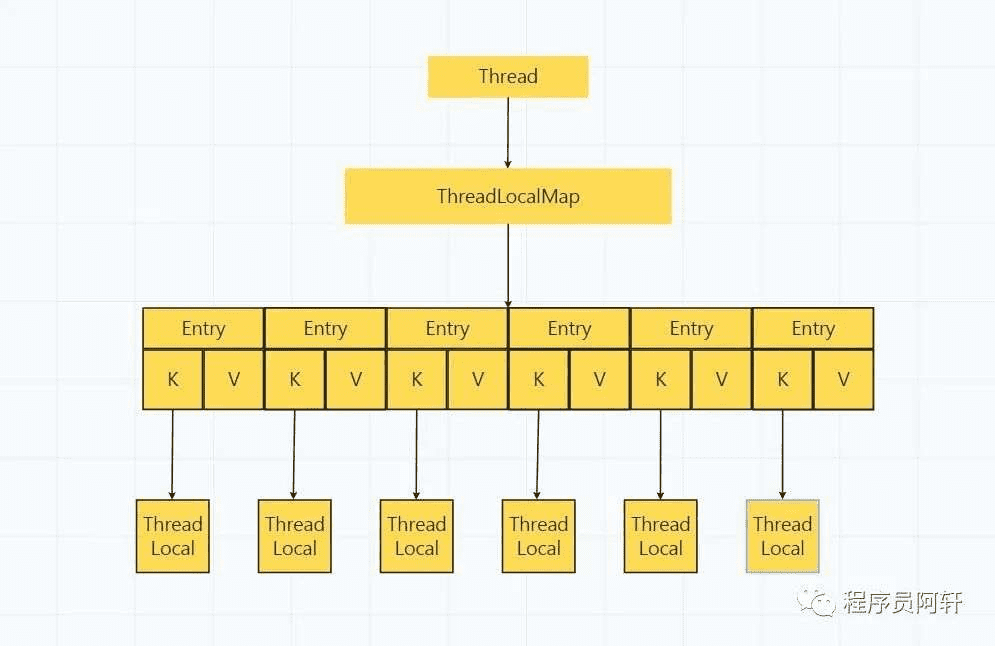
ThreadLocal
说起ThreadLocal,我们在日常开发工作中使用的还是蛮多的。
例如,当用户登录时,我们可以通过ThreadLocal保存用户的信息,而不必每次使用时都再次检查。
spring中的声明式事务也使用ThreadLocal来保存数据库链接,以便多个SQL语句使用同一个数据库链接来保证事务。
数据库链接
好啦,废话不多说,开始吧。
先看一下ThreadLocal
在Thread类中保存一个变量ThreadLocalMap
ThreadLocalMap
/* 与该线程相关的ThreadLocal值。该映射由 ThreadLocal 类维护 *。 */ThreadLocal.ThreadLocalMap threadLocals = null;
ThreadLocalMap是ThreadLocal的内部类。底层数据结构是一个数组
数组
/** * 根据需要调整表格大小。 * table.length 必须始终是 2 的幂。 */private Entry[] table;
元素是Entry类,它是ThreadLocalMap的内部类,并继承WeakReference类别
Entry
WeakReference
static class Entry extends WeakReference> { /** 与此 ThreadLocal 关联的值。 */ Object value; Entry(ThreadLocal k, 对象 v) { super(k); 可以看到,Entry中的k是弱引用,也就是ThreadLocal ,而值仍然是强引用,我们平时所说的内存泄漏的原因也在这个地方,后面会讲到。 好了,我们介绍了ThreadLocal的整体结构,下面我们开始看它的核心方法。 套装 public void set(T值){线程t = Thread.currentThread();ThreadLocalMap映射= getMap(t); 如果 (map != null) map.set(this, value); else createMap(t, value); } 第一个是设置方法。当我们使用ThreadLocal时,我们必须先保存,然后再检索,所以我们先看看它是如何保存的。 首先调用getMap方法获取当前线程保存的ThreadLocalMapThreadLocalMap getMap(Thread t) { return t.threadLocals;} 刚才说了,Thread类存储了一个变量ThreadLocalMap 如果为空,执行初始化 void createMap(Thread t, TfirstValue) { t.threadLocals = new ThreadLocalMap(this,firstValue);} 调用ThreadLocalMap的构造函数 ThreadLocalMap(ThreadLocalfirstKey, 对象firstValue) {table = new Entry[INITIAL_CAPACITY];int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); 表[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY);} 这里我们可以看到ThreadLocalMap的底层数据结构是数组。 首先构造一个条目数组,默认长度为16,然后计算数组下标。 private final int threadLocalHashCode = nextHashCode();private static AtomicInteger nextHashCode = new AtomicInteger();private static final int HASH_INCRMENT = 0x61c88647;private static int nextHashCode( ) { return nextHashCode.getAndAdd(HASH_INCRMENT);} ThreadLocal 的 hash 值是一个名为 threadLocalHashCode 的变量,它调用 nextHashCode 方法,该方法调用另一个AtomicInteger getAndAdd 静态实例的方法。 注意,这个nextHashCode变量是static,即一个新的ThreadLocal实例 ,他的hashcode都是基于在之前的基础上添加 HASH_INCRMENT。 让我们看一下shash_increment的变量,该值为0x61C88647,并且将其转换为10 -in -in -made。 看到这里,小伙伴们自然会有一个疑问,为什么每次hashcode都会把这个值加上上一个呢? 我们先来看一个小实验public static void main(String[] args) { int a = 0x61c88647; int len = 16;for (int i = 1; i < len + 1; i++) { System.out.println(i + " " + ((a*i) & (len-1))); } 这个程序模拟了16ThreadLocal实例的不断创建,以及他的下标的分配。看看结果如何 实际上没有重复 的下标 ,请使用长度为 32 重试并查看 一样,没有下标重复,是不是很神奇 这实际上包含了一些数学原理。我们先来看看这个数字是怎么来的 对上面的公式进行变换,(long)((1<<31) * (Math.sqrt(5)-1)/2 * 2);(Math.sqrt(5)-1)/2这个值是多少? 擅长数字的朋友可能马上想到了,这不就是我们初中学过的黄金分割吗0.618! 所以,为什么每次hashcode递增1640531527,计算出的下标都会均匀分布。这就是原因。有兴趣的朋友可以研究一下。 我们继续往下看。初始化完成后,会调用setThreshold方法设置扩展阈值 private void setThreshold(int len) { 阈值 = len * 2 / 3;} 这里的阈值和HashMap不同。 HashMap 被设置了 3/4 次。这是2/3 。 第一次初始化后,ThreadLocalMap的set方法将在第二次调用时调用。private void set(ThreadLocal key, 对象值) { Entry[] tab = table; int len = tab.length; int i = key .threadLocalHashCode & (len-1); for(条目 e = tab[i]; e != null; e = tab[i = nextIndex(i, len )]) { ThreadLocal k = e.get(); if(k == 键) { e.value = 值; 返回; } if(k == null) { replaceStaleEntry(key, value, i); return; } } tab[i] = new Entry(key, value); int sz = ++size; if(!cleanSomeSlots(i, sz) && sz >=阈值) rehash();} 和HashMap一样,循环遍历队列,查找符合条件的key,nextIndex是获取队列的下一个 private static int nextIndex(int i, int len) { return ((i + 1 < len) ? i + 1 : 0);}因为数组是有界的,所以当遍历超出数组的范围时,就会返回到0下标。 循环中存在2 个判断。第一个判断键是否等于。如果相等,则直接覆盖值。 价值。 第二个判断k是否为空。如果为空,则 将 替换为当前数组位的值。 这里注意,当前索引Entry的key为空,但是value不为null,我们来说说前面提到的内存泄漏问题。 在java中分为4种引用,强弱弱四大法王,强引用是我们日常工作中使用的参考资料当User a = new User()时,a为强引用,软引用使用SoftReference包装,弱引用使用弱引用包装,Phantom Reference 使用PhantomReference 包装。 虚拟引用一般用于链接堆外对象,通过虚拟引用实现堆外内存的回收。 弱引用每次GC都会被回收,而软引用只有在发生时才会被回收 内存不足时才会被回收。 ThreadLocalMap中的Entry的key被弱引用修改,所以每次GC都会是 回收 ,从而产生key变为null,value是对的强引用,不会被回收,但此时的值已经没有任何意义了,只是占用内存徒劳,所以结果这部分内存无法正常使用,造成内存泄漏。 好,我们继续往下看。 其实从这里可以看出,ThreadLocal使用线性检测方法来处理哈希冲突 ,即如果计算出的索引位被别人占用了,那么看下一位是否被占用,继续寻找没有被占用的或者key为null的的。 看他的替换方法replaceStaleEntryprivate void replaceStaleEntry(ThreadLocal key, 对象值, int staleSlot) { 条目[] tab = 表; int len = tab.length; 条目e;int slotToExpunge = staleSlot; for(int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex( i, len)) if (e.get() == null) slotToExpunge = i; for(int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal k = e.get(); if(k == 键) { e.value = 值; tab[i] = tab[staleSlot]; tab[staleSlot] = e; //从先前的过时条目开始删除if存在 if(slotToExpunge == staleSlot) slotToExpunge = i;cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; if (k == null && slotToExpunge == staleSlot) slotToExpunge = i; } // 如果找不到 key,则将新条目 放入 stale slot tab[staleSlot ].value = null; tab[staleSlot] = 新条目(键, value); // 如果在运行中,删除它们 if (slotToExpunge != staleSlot) “ cleanSomeSlots (expungeStaleEntry( slotToExpunge), len);}这个方法有点长,我们仔细看看。 首先看的第一个for循环。我们现在知道当前数组下标的key为空,会被回收 是的,那我看看有没有条目 键为空。如果是的话,我把它们全部回收不是更好吗?因此,这个 for 的函数是 向前遍历 。如果找到key==null,记录位置并赋值给slotToExpunge。当Entry为null时停止,否则向前遍历。当遍历到第一个元素时,会跳转到数组的末尾,继续向前遍历。 这里有的朋友可能会想,如果我从来没有遇到过Entry为null,是不是会遍历回自己呢? 显然,没有。 你忘了吗?当数组的元素个数达到一定值时,就会扩大容量,所以数组中总会有一些出价较低的。 空。 再看第二个for循环,这次开始向后遍历,如果找到符合条件的key,则 覆盖值 ,将当前索引元素和staleSlot索引元素替换为,画个图来理解 因为staleSlot索引位键为空,稍后会被清除,所以将其替换为覆盖该值的i位。然后判断上次遍历时key是否为null。如果没有,请将开始清洁的位置设置为i,否则从之前找到的索引位置开始清洁。 ThreadLocal清理的方式有2种,先看里面的,expungeStaleEntry方法private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length; //删除 staleSlot 处的条目 选项卡[staleSlot].value = null; tab[staleSlot] = null; size--; //重复,直到遇到 null 条目 e; int i; 对于 (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal k = e。 get(); if(k == null) { e.value = null; tab[i] = null; 尺寸--; } else { int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null; // 与 Knuth 6.4 算法 R 不同,我们必须扫描直到 // null 因为多个条目可能已经过时。 同时(tab[h] != null) } } 返回 i;}因为清理是从staleSlot开始的,所以元素位于 staleSlot 位置的内容一开始就被清除。 然后向后遍历,如果key为空则直接清除。 如果不为空,则计算索引位。如果你发现计算出的索引位不是你当前的位置,那么说明你设置的时候,计算出的索引位被 占用,被迫向后遍历。 然后,将当前 i 位设置为 null 为什么设置为null? 因为此时一些key为null的元素已经被清除掉了,原来占据他位置的元素很有可能被清除掉了,所以他要拿回属于他的东西, 紧接着,他开始循环,从计算出的h开始,直到找到空出的位置 直到。 最后返回i。请注意,该 i 位元素为 null。 回到外层再次清理,调用cleanSomeSlots方法private boolean cleanSomeSlots(int i, int n) {布尔值已删除=false;条目[]选项卡=表;int len = 制表符长度; do { ======================================================================================================================================================================== if (e != null && e.get() == null) { 与 i = expungeStaleEntry(i) ; ( (n >>>= 1) != 0); 返回;删除} 这里注意,因为当前i元素为null,所以从下一位开始遍历。如果发现key为如果为null,则再次调用之前的expungeStaleEntry方法开始清理。 如果找不到null,那么会循环log2^n次,如果找到,则重新赋值n = len,再次循环 log2^n 次。 再次返回外层方法。如果key不满足条件,则判断key是否为空。如果为空,则判断,并向前遍历。 您是否发现过键为空的条目?如果没有,请设置开始清洁的位置。 遍历,直到元素为null。如果没有找到满足条件的元素,则跳出循环。添加新的 Entry 并将其插入到 staleSlot 位置。因为上一次循环没有找到匹配的key,也没有进行清理工作,所以此时会进行cleanup。和之前循环调用的方法cleanSomeSlots(expungeStaleEntry(slotToExpunge), len)是一样的。 回到最开始的设置方法。如果循环中没有找到满足条件的key,并且key为null,则构造一个En。尝试将 元素分配到 i 位置。 一般添加一个元素后,会判断是否需要扩展,所以扩展这时候也会进行判断,但是在扩展之前,会进行一次随机清理做完了。如果key恰好被清理了null个元素,那么因为元素被清理了,数组数量减少了,不需要判断扩容了。如果没有清除,则此时判断是否超过阈值,超过进行扩容。调用 rehash 方法 private void rehash() { expungeStaleEntries(); // 使用较低的阈值 来避免加倍以避免迟滞 if(大小 >= 阈值 - 阈值 / 4) resize();} 在实际扩容之前,会先将数组遍历一遍一次,并且将null的元素清除, expungeStaleEntries 这个方法private void expungeStaleEntries() { Entry[] tab = table; int len= tab.length; 对于(int j = 0 ; j < len; j++) { 条目 e = tab[j]; if (e != null && e.get() == null) expungeStaleEntry(j ); }} 如您所见,数组从头到尾被遍历。如果键为 null,则调用 expungeStaleEntry。 清理干净。 清洁完毕后,判断是否超过阈值。这里,阈值降低为原来的3/4。 笔者可能会认为,清洗后,如果元素数量仍然超过3/4的阈值,那么短时间内肯定会超过2/3。与其到时候还不如现在就扩容,提前扩容。 拨打调整大小以展开private void 调整大小() { 条目[] oldTab = table; int oldLen = oldTab.length; int newLen = oldLen * 2; 条目[ ] newTab = 新条目[newLen]; int count = 0; for(int j = 0; j < 旧Len; ++j) { 条目 e = oldTab[ j]; if(e != null) { ThreadLocalk = e.get() ; if(k == null ) { e.value = null; // 帮助 GC } else { int h = k.threadLocalHashCode & (newLen - 1); while(newTab[h] != null) h = nextIndex(h, newLen); newTab[h] = e; count++; } } } setThreshold(newLen); 大小 = 计数; 表格 = 新选项卡;} 这个方法比较简单,就是把数据库容量扩大一倍,然后把老内存的元素转移到新的仓库上,到这里我们就分析完了set方法。现在我们看一下get方法 得到 public T get() {线程 t = Thread.currentThread();if (地图, @SuppressWarnings(“未选中”) T 结果 = (T)e.value; | }
static class Entry extends WeakReference> { /** 与此 ThreadLocal 关联的值。 */ Object value; Entry(ThreadLocal k, 对象 v) { super(k); 可以看到,Entry中的k是弱引用,也就是ThreadLocal ,而值仍然是强引用,我们平时所说的内存泄漏的原因也在这个地方,后面会讲到。 好了,我们介绍了ThreadLocal的整体结构,下面我们开始看它的核心方法。 套装 public void set(T值){线程t = Thread.currentThread();ThreadLocalMap映射= getMap(t); 如果 (map != null) map.set(this, value); else createMap(t, value); } 第一个是设置方法。当我们使用ThreadLocal时,我们必须先保存,然后再检索,所以我们先看看它是如何保存的。 首先调用getMap方法获取当前线程保存的ThreadLocalMapThreadLocalMap getMap(Thread t) { return t.threadLocals;} 刚才说了,Thread类存储了一个变量ThreadLocalMap 如果为空,执行初始化 void createMap(Thread t, TfirstValue) { t.threadLocals = new ThreadLocalMap(this,firstValue);} 调用ThreadLocalMap的构造函数 ThreadLocalMap(ThreadLocalfirstKey, 对象firstValue) {table = new Entry[INITIAL_CAPACITY];int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); 表[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY);} 这里我们可以看到ThreadLocalMap的底层数据结构是数组。 首先构造一个条目数组,默认长度为16,然后计算数组下标。 private final int threadLocalHashCode = nextHashCode();private static AtomicInteger nextHashCode = new AtomicInteger();private static final int HASH_INCRMENT = 0x61c88647;private static int nextHashCode( ) { return nextHashCode.getAndAdd(HASH_INCRMENT);} ThreadLocal 的 hash 值是一个名为 threadLocalHashCode 的变量,它调用 nextHashCode 方法,该方法调用另一个AtomicInteger getAndAdd 静态实例的方法。 注意,这个nextHashCode变量是static,即一个新的ThreadLocal实例 ,他的hashcode都是基于在之前的基础上添加 HASH_INCRMENT。 让我们看一下shash_increment的变量,该值为0x61C88647,并且将其转换为10 -in -in -made。 看到这里,小伙伴们自然会有一个疑问,为什么每次hashcode都会把这个值加上上一个呢? 我们先来看一个小实验public static void main(String[] args) { int a = 0x61c88647; int len = 16;for (int i = 1; i < len + 1; i++) { System.out.println(i + " " + ((a*i) & (len-1))); } 这个程序模拟了16ThreadLocal实例的不断创建,以及他的下标的分配。看看结果如何 实际上没有重复
可以看到,Entry中的k是弱引用,也就是ThreadLocal ,而值仍然是强引用,我们平时所说的内存泄漏的原因也在这个地方,后面会讲到。
弱引用
ThreadLocal ,而值仍然是强引用,我们平时所说的内存泄漏的原因也在这个地方,后面会讲到。
值
强引用
内存泄漏
好了,我们介绍了ThreadLocal的整体结构,下面我们开始看它的核心方法。
public void set(T值){线程t = Thread.currentThread();ThreadLocalMap映射= getMap(t); 如果 (map != null) map.set(this, value); else createMap(t, value); }
第一个是设置方法。当我们使用ThreadLocal时,我们必须先保存,然后再检索,所以我们先看看它是如何保存的。
设置
首先调用getMap方法获取当前线程保存的ThreadLocalMap
getMap
ThreadLocalMap getMap(Thread t) { return t.threadLocals;}
刚才说了,Thread类存储了一个变量ThreadLocalMap
如果为空,执行初始化
初始化
void createMap(Thread t, TfirstValue) { t.threadLocals = new ThreadLocalMap(this,firstValue);}
调用ThreadLocalMap的构造函数
构造函数
ThreadLocalMap(ThreadLocalfirstKey, 对象firstValue) {table = new Entry[INITIAL_CAPACITY];int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); 表[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY);}
这里我们可以看到ThreadLocalMap的底层数据结构是数组。
首先构造一个条目数组,默认长度为16,然后计算数组下标。
条目数组
16
数组下标
private final int threadLocalHashCode = nextHashCode();private static AtomicInteger nextHashCode = new AtomicInteger();private static final int HASH_INCRMENT = 0x61c88647;private static int nextHashCode( ) { return nextHashCode.getAndAdd(HASH_INCRMENT);}
ThreadLocal 的 hash 值是一个名为 threadLocalHashCode 的变量,它调用 nextHashCode 方法,该方法调用另一个AtomicInteger getAndAdd 静态实例的方法。
hash
threadLocalHashCode
nextHashCode
AtomicInteger getAndAdd 静态实例的方法。
getAndAdd
注意,这个nextHashCode变量是static,即一个新的ThreadLocal实例 ,他的hashcode都是基于在之前的基础上添加 HASH_INCRMENT。
static
ThreadLocal实例 ,他的hashcode都是基于在之前的基础上添加 HASH_INCRMENT。
hashcode
HASH_INCRMENT
让我们看一下shash_increment
0x61C88647
看到这里,小伙伴们自然会有一个疑问,为什么每次hashcode都会把这个值加上上一个呢?
疑问
我们先来看一个小实验
小实验
public static void main(String[] args) { int a = 0x61c88647; int len = 16;for (int i = 1; i < len + 1; i++) { System.out.println(i + " " + ((a*i) & (len-1))); }
这个程序模拟了16ThreadLocal实例的不断创建,以及他的下标的分配。看看结果如何
下标
实际上没有重复
,请使用长度为 32 重试并查看 一样,没有下标重复,是不是很神奇 这实际上包含了一些数学原理。我们先来看看这个数字是怎么来的 对上面的公式进行变换,(long)((1<<31) * (Math.sqrt(5)-1)/2 * 2);(Math.sqrt(5)-1)/2这个值是多少? 擅长数字的朋友可能马上想到了,这不就是我们初中学过的黄金分割吗0.618! 所以,为什么每次hashcode递增1640531527,计算出的下标都会均匀分布。这就是原因。有兴趣的朋友可以研究一下。 我们继续往下看。初始化完成后,会调用setThreshold方法设置扩展阈值 private void setThreshold(int len) { 阈值 = len * 2 / 3;} 这里的阈值和HashMap不同。 HashMap 被设置了 3/4 次。这是2/3 。 第一次初始化后,ThreadLocalMap的set方法
32
一样,没有下标重复,是不是很神奇
重复
这实际上包含了一些数学原理。我们先来看看这个数字是怎么来的
数学原理
对上面的公式进行变换,(long)((1<<31) * (Math.sqrt(5)-1)/2 * 2);
(long)((1<<31) * (Math.sqrt(5)-1)/2 * 2)
(Math.sqrt(5)-1)/2这个值是多少?
(Math.sqrt(5)-1)/2
擅长数字的朋友可能马上想到了,这不就是我们初中学过的黄金分割吗0.618!
黄金分割
0.618
所以,为什么每次hashcode递增1640531527,计算出的下标都会均匀分布。这就是原因。有兴趣的朋友可以研究一下。
1640531527
我们继续往下看。初始化完成后,会调用setThreshold方法设置扩展阈值
setThreshold
扩展阈值
private void setThreshold(int len) { 阈值 = len * 2 / 3;}
这里的阈值和HashMap不同。 HashMap 被设置了 3/4 次。这是2/3 。
HashMap
3/4
2/3
第一次初始化后,ThreadLocalMap的set方法
set
private void set(ThreadLocal key, 对象值) { Entry[] tab = table; int len = tab.length; int i = key .threadLocalHashCode & (len-1); for(条目 e = tab[i]; e != null; e = tab[i = nextIndex(i, len )]) { ThreadLocal k = e.get(); if(k == 键) { e.value = 值; 返回; } if(k == null) { replaceStaleEntry(key, value, i); return; } } tab[i] = new Entry(key, value); int sz = ++size; if(!cleanSomeSlots(i, sz) && sz >=阈值) rehash();}
和HashMap一样,循环遍历队列,查找符合条件的key,nextIndex是获取队列的下一个
nextIndex
private static int nextIndex(int i, int len) { return ((i + 1 < len) ? i + 1 : 0);}
因为数组是有界的,所以当遍历超出数组的范围时,就会返回到0下标。
有界的
2 个判断。第一个判断键是否等于。如果相等,则直接覆盖值。 价值。
2 个判断
键是否等于
直接覆盖值。 价值。
第二个判断k是否为空。如果为空,则 将 替换为当前数组位的值。
k是否为空
将
这里注意,当前索引Entry的key为空,但是value不为null,我们来说说前面提到的内存泄漏问题。
key
value
在java中分为4种引用,强弱弱四大法王,强引用是我们日常工作中使用的参考资料当User a = new User()时,a为强引用,软引用使用SoftReference包装,弱引用使用弱引用包装,Phantom Reference 使用PhantomReference 包装。
强弱弱
软引用
SoftReference
Phantom Reference
PhantomReference
虚拟引用一般用于链接堆外对象,通过虚拟引用实现堆外内存的回收。 弱引用每次GC都会被回收,而软引用只有在发生时才会被回收 内存不足时才会被回收。
堆外对象
堆外内存
GC
ThreadLocalMap中的Entry的key被弱引用修改,所以每次GC都会是 回收 ,从而产生key变为null,value是对的强引用,不会被回收,但此时的值已经没有任何意义了,只是占用内存徒劳,所以结果这部分内存无法正常使用,造成内存泄漏。
好,我们继续往下看。
其实从这里可以看出,ThreadLocal使用线性检测方法来处理哈希冲突 ,即如果计算出的索引位被别人占用了,那么看下一位是否被占用,继续寻找没有被占用的或者key为null的的。
线性检测方法来处理哈希冲突 ,即如果计算出的索引位被别人占用了,那么看下一位是否被占用,继续寻找没有被
哈希冲突
或者key为null的
。
看他的替换方法replaceStaleEntry
replaceStaleEntry
private void replaceStaleEntry(ThreadLocal key, 对象值, int staleSlot) { 条目[] tab = 表; int len = tab.length; 条目e;int slotToExpunge = staleSlot; for(int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex( i, len)) if (e.get() == null) slotToExpunge = i; for(int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal k = e.get(); if(k == 键) { e.value = 值; tab[i] = tab[staleSlot]; tab[staleSlot] = e; //从先前的过时条目开始删除if存在 if(slotToExpunge == staleSlot) slotToExpunge = i;cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; if (k == null && slotToExpunge == staleSlot) slotToExpunge = i; } // 如果找不到 key,则将新条目 放入 stale slot tab[staleSlot ].value = null; tab[staleSlot] = 新条目(键, value); // 如果在运行中,删除它们 if (slotToExpunge != staleSlot) “ cleanSomeSlots (expungeStaleEntry( slotToExpunge), len);}
这个方法有点长,我们仔细看看。
首先看的第一个for循环。我们现在知道当前数组下标的key为空,会被回收 是的,那我看看有没有条目 键为空。如果是的话,我把它们全部回收不是更好吗?因此,这个 for 的函数是 向前遍历 。如果找到key==null,记录位置并赋值给slotToExpunge。当Entry为null时停止,否则向前遍历。当遍历到第一个元素时,会跳转到数组的末尾,继续向前遍历。
的第一个for循环
回收
条目
向前遍历
slotToExpunge
这里有的朋友可能会想,如果我从来没有遇到过Entry为null,是不是会遍历回自己呢?
显然,没有。
再看第二个for循环,这次开始向后遍历,如果找到符合条件的key,则 覆盖值 ,将当前索引元素和staleSlot索引元素替换为,画个图来理解
开始向后遍历
覆盖值 ,将当前索引元素和staleSlot索引元素替换为,画个图来理解
替换为
因为staleSlot索引位键为空,稍后会被清除,所以将其替换为覆盖该值的i位。然后判断上次遍历时key是否为null。如果没有,请将开始清洁的位置设置为i,否则从之前找到的索引位置开始清洁。
staleSlot
i
开始清洁的位置设置为i,否则从之前找到的索引位置开始清洁。
设置为i,否则从之前找到的索引位置开始清洁。
ThreadLocal清理的方式有2种,先看里面的,expungeStaleEntry方法
expungeStaleEntry
private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length; //删除 staleSlot 处的条目 选项卡[staleSlot].value = null; tab[staleSlot] = null; size--; //重复,直到遇到 null 条目 e; int i; 对于 (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal k = e。 get(); if(k == null) { e.value = null; tab[i] = null; 尺寸--; } else { int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null; // 与 Knuth 6.4 算法 R 不同,我们必须扫描直到 // null 因为多个条目可能已经过时。 同时(tab[h] != null) } } 返回 i;}
因为清理是从staleSlot开始的,所以元素位于 staleSlot 位置的内容一开始就被清除。
然后向后遍历,如果key为空则直接清除。
向后遍历
清除
如果不为空,则计算索引位。如果你发现计算出的索引位不是你当前的位置,那么说明你设置的时候,计算出的索引位被 占用,被迫向后遍历。
然后,将当前 i 位设置为 null
null
为什么设置为null?
因为此时一些key为null的元素已经被清除掉了,原来占据他位置的元素很有可能被清除掉了,所以他要拿回属于他的东西, 紧接着,他开始循环,从计算出的h开始,直到找到空出的位置 直到。 最后返回i。请注意,该 i 位元素为 null。 回到外层再次清理,调用cleanSomeSlots方法private boolean cleanSomeSlots(int i, int n) {布尔值已删除=false;条目[]选项卡=表;int len = 制表符长度; do { ======================================================================================================================================================================== if (e != null && e.get() == null) { 与 i = expungeStaleEntry(i) ; ( (n >>>= 1) != 0); 返回;删除} 这里注意,因为当前i元素为null,所以从下一位开始遍历。如果发现key为如果为null,则再次调用之前的expungeStaleEntry方法开始清理。 如果找不到null,那么会循环log2^n次,如果找到,则重新赋值n = len,再次循环 log2^n 次。 再次返回外层方法。如果key不满足条件,则判断key是否为空。如果为空,则判断,并向前遍历。 您是否发现过键为空的条目?如果没有,请设置开始清洁的位置。 遍历,直到元素为null。如果没有找到满足条件的元素,则跳出循环。添加新的 Entry 并将其插入到 staleSlot 位置。因为上一次循环没有找到匹配的key,也没有进行清理工作,所以此时会进行cleanup。和之前循环调用的方法cleanSomeSlots(expungeStaleEntry(slotToExpunge), len)是一样的。 回到最开始的设置方法。如果循环中没有找到满足条件的key,并且key为null,则构造一个En。尝试将 元素分配到 i 位置。 一般添加一个元素后,会判断是否需要扩展,所以扩展这时候也会进行判断,但是在扩展之前,会进行一次随机清理做完了。如果key恰好被清理了null个元素,那么因为元素被清理了,数组数量减少了,不需要判断扩容了。如果没有清除,则此时判断是否超过阈值,超过进行扩容。调用 rehash 方法 private void rehash() { expungeStaleEntries(); // 使用较低的阈值 来避免加倍以避免迟滞 if(大小 >= 阈值 - 阈值 / 4) resize();} 在实际扩容之前,会先将数组遍历一遍一次,并且将null的元素清除, expungeStaleEntries 这个方法private void expungeStaleEntries() { Entry[] tab = table; int len= tab.length; 对于(int j = 0 ; j < len; j++) { 条目 e = tab[j]; if (e != null && e.get() == null) expungeStaleEntry(j ); }} 如您所见,数组从头到尾被遍历。如果键为 null,则调用 expungeStaleEntry。 清理干净。 清洁完毕后,判断是否超过阈值。这里,阈值降低为原来的3/4。 笔者可能会认为,清洗后,如果元素数量仍然超过3/4的阈值,那么短时间内肯定会超过2/3。与其到时候还不如现在就扩容,提前扩容。 拨打调整大小以展开private void 调整大小() { 条目[] oldTab = table; int oldLen = oldTab.length; int newLen = oldLen * 2; 条目[ ] newTab = 新条目[newLen]; int count = 0; for(int j = 0; j < 旧Len; ++j) { 条目 e = oldTab[ j]; if(e != null) { ThreadLocalk = e.get() ; if(k == null ) { e.value = null; // 帮助 GC } else { int h = k.threadLocalHashCode & (newLen - 1); while(newTab[h] != null) h = nextIndex(h, newLen); newTab[h] = e; count++; } } } setThreshold(newLen); 大小 = 计数; 表格 = 新选项卡;} 这个方法比较简单,就是把数据库容量扩大一倍,然后把老内存的元素转移到新的仓库上,到这里我们就分析完了set方法。现在我们看一下get方法 得到 public T get() {线程 t = Thread.currentThread();if (地图, @SuppressWarnings(“未选中”) T 结果 = (T)e.value; | }
清除掉了
紧接着,他开始循环,从计算出的h开始,直到找到空出的位置 直到。
循环
h
空出的位置 直到。
最后返回i。请注意,该 i 位元素为 null。
回到外层再次清理,调用cleanSomeSlots方法
cleanSomeSlots
private boolean cleanSomeSlots(int i, int n) {布尔值已删除=false;条目[]选项卡=表;int len = 制表符长度; do { ======================================================================================================================================================================== if (e != null && e.get() == null) { 与 i = expungeStaleEntry(i) ; ( (n >>>= 1) != 0); 返回;删除}
这里注意,因为当前i元素为null,所以从下一位开始遍历。如果发现key为如果为null,则再次调用之前的expungeStaleEntry方法开始清理。
如果为null
如果找不到null,那么会循环log2^n次,如果找到,则重新赋值n = len,再次循环 log2^n 次。
log2^n
,则重新赋值n = len
再次返回外层方法。如果key不满足条件,则判断key是否为空。如果为空,则判断,并向前遍历。 您是否发现过键为空的条目?如果没有,请设置开始清洁的位置。
key不满足条件
key是否为空
,并向前遍历。
键为空
遍历,直到元素为null。如果没有找到满足条件的元素,则跳出循环。添加新的 Entry 并将其插入到 staleSlot 位置。因为上一次循环没有找到匹配的key,也没有进行清理工作,所以此时会进行cleanup。和之前循环调用的方法cleanSomeSlots(expungeStaleEntry(slotToExpunge), len)是一样的。
跳出循环
cleanup
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len)
回到最开始的设置方法。如果循环中没有找到满足条件的key,并且key为null,则构造一个En。尝试将 元素分配到 i 位置。
En。尝试将
一般添加一个元素后,会判断是否需要扩展,所以扩展这时候也会进行判断,但是在扩展之前,会进行一次随机清理做完了。如果key恰好被清理了null个元素,那么因为元素被清理了,数组数量减少了,不需要判断扩容了。如果没有清除,则此时判断是否超过阈值,超过进行扩容。调用 rehash 方法
扩展
随机清理
是否超过阈值
rehash
private void rehash() { expungeStaleEntries(); // 使用较低的阈值 来避免加倍以避免迟滞 if(大小 >= 阈值 - 阈值 / 4) resize();}
在实际扩容之前,会先将数组遍历一遍一次,并且将null的元素清除, expungeStaleEntries 这个方法
遍历一遍
expungeStaleEntries
private void expungeStaleEntries() { Entry[] tab = table; int len= tab.length; 对于(int j = 0 ; j < len; j++) { 条目 e = tab[j]; if (e != null && e.get() == null) expungeStaleEntry(j ); }}
如您所见,数组从头到尾被遍历。如果键为 null,则调用 expungeStaleEntry。 清理干净。
从头到尾
expungeStaleEntry。
清洁完毕后,判断是否超过阈值。这里,阈值降低为原来的3/4。
笔者可能会认为,清洗后,如果元素数量仍然超过3/4的阈值,那么短时间内肯定会超过2/3。与其到时候还不如现在就扩容,提前扩容。
,提前扩容
拨打调整大小以展开
调整大小
private void 调整大小() { 条目[] oldTab = table; int oldLen = oldTab.length; int newLen = oldLen * 2; 条目[ ] newTab = 新条目[newLen]; int count = 0; for(int j = 0; j < 旧Len; ++j) { 条目 e = oldTab[ j]; if(e != null) { ThreadLocalk = e.get() ; if(k == null ) { e.value = null; // 帮助 GC } else { int h = k.threadLocalHashCode & (newLen - 1); while(newTab[h] != null) h = nextIndex(h, newLen); newTab[h] = e; count++; } } } setThreshold(newLen); 大小 = 计数; 表格 = 新选项卡;}
这个方法比较简单,就是把数据库容量扩大一倍,然后把老内存的元素转移到新的仓库上,
转移
到这里我们就分析完了set方法。现在我们看一下get方法
get
public T get() {线程 t = Thread.currentThread();
get方法比较简单。首先获取当前线程的ThreadLocalMap变量。如果为null,则调用setInitialValue进行初始化。
setInitialValue
private T setInitialValue() { T value = initialValue();Thread t = Thread.currentThread(); ThreadLocalMap map = getMap( t); if (map != null) map.set(this, value); else createMap(t, value); ''' ' 值;}
initialValue方法返回一个null,然后调用前面提到的createMap方法继续 初始化。
initialValue
createMap
如果ThreadLocalMap变量不为空,则调用getEntry获取Entry元素。
getEntry
private Entry getEntry(ThreadLocal key) { int i = key.threadLocalHashCode & (table.length - 1); Entry e = table[i] ; 如果 (e != null && e.get() == key) return e; else 返回 getEntryAfterMiss(键, i, e);}
这里,如果满足计算出的第i个索引位,则返回,否则调用getEntryAfterMiss方法
getEntryAfterMiss
private Entry getEntryAfterMiss(ThreadLocal key, int i, Entry e) { Entry[] tab = table; int len= tab.length; 同时 (e != null) { ThreadLocal k = e.get(); if (k == key) 返回 e; if (k == null) else i]; } 返回 null;}
如果e为null,则表示GC已被回收,并返回null。否则,从i开始向后遍历,满足条件则返回。如果找到null,则清理直到e==null或找到迄今为止满足条件的。
e==null
最后返回get方法,判断是否找到满足条件的Entry。如果找到,则返回。如果没有找到,继续调用 setInitialValue 方法,将当前 ThreadLocal 实例作为 key,null 为用作值,构造一个 Entry 并将其插入阵列中。
最后看去除方法
去除
public void remove() { ThreadLocalMap m = getMap(Thread.currentThread()); if (米!=空) 米.remove(this);}
调用ThreadLocalMap的删除方法
删除
private void remove(ThreadLocal key) { Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode&(len-1); for (条目 e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { if (e.get() == key) { e.clear(); expungeStaleEntry(i); 返回; } }}
计算出当前ThreadLocal实例所在的i索引位,确定此位置的key是否是自己,是,就删除,然后调用expungeStaleEntry方法看看能不能清理掉一些元素,然后返回。
在日常工作中,如果线上出现问题,我们需要排查问题。现在微服务盛行,很多项目被传统的单体拆分完成了对于微服务来说,来自客户端的一个请求往往会经过多个系统。这时,为了跟踪整个链路的调用情况,我们通常会创建一个traceId,贯穿整个调用链路。这样,我们在检查log时,就可以通过这个traceId将整个调用过程连接在一起。
traceId
但为了提高系统的快速响应能力,我们经常创建线程池用于异步执行。这个时候,如果恰好是线程池执行的话,traceId就会被中断。如果发生错误,则无法追踪。
线程池
这时候ThreadLocal就派上用场了。
在log框架slf4j有一个叫做MDC 类,通过它我们可以实现我们需要的功能。
slf4j
MDC 类,通过它我们可以实现我们需要的功能。
我们先看一下正常情况下的调用流程。
/** * @author 程序员阿轩 */@Componentpublic class WebFilter extends GenericFilterBean { Logger logger = LoggerFactory.getLogger(WebFilter.class); @Override public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) { System.out.println("WebFilter doFilter-----------"); try { HttpServletRequest request = (HttpServletRequest) servletRequest; String traceId = request.getHeader(TraceConstants.X_COMMON_TRACE_ID); if (StrUtil.isBlank(traceId)) { traceId = TraceUtils.newTraceId(); } TraceContext.setTraceId(traceId); System.out.println("WebFilter traceId ->" + traceId); filterChain.doFilter(servletRequest, servletResponse); } catch (Throwable e) { } finally { TraceContext.clear(); } }}
首先请求来到过滤器,我们在这里给他设置一个traceId
/** * @author 程序员阿轩 */public class TraceContext { private TraceContext() { } public static String getTraceId() { return MDC.get(TraceConstants.X_COMMON_TRACE_ID); } public static void setTraceId(String traceId) { MDC.put(TraceConstants.X_COMMON_TRACE_ID, traceId); } public static Map getContextMap() { return MDC.getCopyOfContextMap(); } public static void setContextMap(Map contextMap) { if (contextMap == null) { contextMap = new HashMap<>(); } MDC.setContextMap(contextMap); } public static void clear() { MDC.remove(TraceConstants.X_COMMON_TRACE_ID); } public static void clearAll() { MDC.clear(); }}
接着请求来到controller
controller
/** * @author 程序员阿轩 */@RestControllerpublic class TraceController { @Autowired private TestService testService; @GetMapping("/trace") public String trace() { System.out.println("main->" + Thread.currentThread().getName()); testService.test(); return "程序员阿轩"; }}
service类
/** * @author 程序员阿轩 */@Servicepublic class TestService { @Async("ecsAsyncExecutor") public void test() { System.out.println("线程池中线程->" + Thread.currentThread().getName() + "---" + MDC.get(TraceConstants.X_COMMON_TRACE_ID)); try { Thread.sleep(500000); } catch (InterruptedException e) { e.printStackTrace(); } }}
线程池配置类
/** * @author 程序员阿轩 */@Configurationpublic class AsyncExecutorConfig implements AsyncConfigurer { private static final Logger LOGGER = LoggerFactory.getLogger(AsyncExecutorConfig.class); private final TaskExecutionProperties properties; public AsyncExecutorConfig(TaskExecutionProperties properties) { this.properties = properties; } @Override @Bean("ecsAsyncExecutor") public ThreadPoolTaskExecutor getAsyncExecutor() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor() { @Override public Future submit(Callable task) { return super.submit(task); } @Override public void execute(Runnable task) { super.execute(task); } }; executor.setCorePoolSize(properties.getPool().getCoreSize()); executor.setMaxPoolSize(properties.getPool().getMaxSize()); executor.setQueueCapacity(properties.getPool().getQueueCapacity()); executor.setAllowCoreThreadTimeOut(properties.getPool().isAllowCoreThreadTimeout()); executor.setKeepAliveSeconds((int) properties.getPool().getKeepAlive().getSeconds()); executor.setThreadNamePrefix(properties.getThreadNamePrefix()); executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); executor.initialize(); return executor; }}
这里主要为了演示,一些异常异常捕捉什么的就省掉了。
yaml配置
spring: task: execution: pool: allow-core-thread-timeout: true core-size: 1 max-size: 5 queue-capacity: 3 keep-alive: 60s thread-name-prefix: a-xuan
运行程序,打印结果
WebFilter doFilter-----------WebFilter traceId ->08dd98a2-7343-4695-b509-2103bda6f7efmain->http-nio-9050-exec-1线程池中线程->a-xuan1---null
可以看到,线程池中的线程获取traceId为null,获取不到。
traceId为null
我们稍微改造下线程池的配置类
/** * @author 程序员阿轩 */@Configurationpublic class AsyncExecutorConfig implements AsyncConfigurer { private static final Logger LOGGER = LoggerFactory.getLogger(AsyncExecutorConfig.class); private final TaskExecutionProperties properties; public AsyncExecutorConfig(TaskExecutionProperties properties) { this.properties = properties; } @Override @Bean("ecsAsyncExecutor") public ThreadPoolTaskExecutor getAsyncExecutor() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor() { @Override public Future submit(Callable task) { return super.submit(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap())); } @Override public void execute(Runnable task) { super.execute(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap())); } }; executor.setCorePoolSize(properties.getPool().getCoreSize()); executor.setMaxPoolSize(properties.getPool().getMaxSize()); executor.setQueueCapacity(properties.getPool().getQueueCapacity()); executor.setAllowCoreThreadTimeOut(properties.getPool().isAllowCoreThreadTimeout()); executor.setKeepAliveSeconds((int) properties.getPool().getKeepAlive().getSeconds()); executor.setThreadNamePrefix(properties.getThreadNamePrefix()); executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); executor.initialize(); return executor; }}
我们把需要执行的任务包装一层
/** * @author 程序员阿轩 */public class ThreadMdcUtil { public static Callable wrap(final Callable callable, final Map context) { return new Callable() { @Override public T call() throws Exception { if (context == null) { MDC.clear(); } else { MDC.setContextMap(context); } System.out.println("wrap: " + Thread.currentThread().getName() + "---" + MDC.get(TraceConstants.X_COMMON_TRACE_ID)); try { return www.sychzs.cn(); } finally { MDC.clear(); } } }; public static Runnable wrap(final Runnable runnable, final Map context) { return () -> { if (context == null) { MDC.clear(); } else { MDC.setContextMap(context); }// System.out.println("wrap: " + Thread.currentThread().getName() + "---" + MDC.get(TraceConstants.X_COMMON_TRACE_ID)); try { www.sychzs.cn(); } finally { MDC.clear(); } }; }}
再次执行看下打印结果
WebFilter doFilter-----------WebFilter traceId ->655795e7-a58e-408b-9758-e65c04aa4e4amain->http-nio-9050-exec-1submit->http-nio-9050-exec-1wrap: a-xuan1---655795e7-a58e-408b-9758-e65c04aa4e4a线程池中线程->a-xuan1---655795e7-a58e-408b-9758-e65c04aa4e4a
可以看到此时线程池中的线程拿到了traceId,从而完成了链路追踪的功能。
下面我们简单看下MDC是怎么实现这个功能的。
MDC
我们看下刚刚使用到的put和get方法
put和get
public static void put(String key, String val) throws IllegalArgumentException { if (key == null) { throw new IllegalArgumentException("key parameter cannot be null"); } else if (mdcAdapter == null) { throw new IllegalStateException("MDCAdapter cannot be null. See also http://www.sychzs.cn/codes.html#null_MDCA"); } else { mdcAdapter.put(key, val); }}
public static String get(String key) throws IllegalArgumentException { if (key == null) { throw new IllegalArgumentException("key parameter cannot be null"); } else if (mdcAdapter == null) { throw new IllegalStateException("MDCAdapter cannot be null. See also http://www.sychzs.cn/codes.html#null_MDCA"); } else { return mdcAdapter.get(key); }}
可以看到,MDC只是个门面,真正发挥作用的是MDCAdapter这个东西。
MDCAdapter
public interface MDCAdapter { void put(String var1, String var2); String get(String var1); void remove(String var1); void clear(); Map getCopyOfContextMap(); void setContextMap(Map var1);}
而MDCAdapter实际上是一个接口,功能由他的子类来实现
现在我们日志框架通常使用的都是LogBack,我们看下LogBack的实现
LogBack
public void put(String key, String val) throws IllegalArgumentException { if (key == null) { throw new IllegalArgumentException("key cannot be null"); } else { Map oldMap = (Map)this.copyOnThreadLocal.get(); Integer lastOp = this.getAndSetLastOperation(1); if (!this.wasLastOpReadOrNull(lastOp) && oldMap != null) { oldMap.put(key, val); } else { Map newMap = this.duplicateAndInsertNewMap(oldMap); newMap.put(key, val); } }}
可以看到,核心是一个Map的变量copyOnThreadLocal,从名字其实已经能够看出来了
copyOnThreadLocal
final ThreadLocal> copyOnThreadLocal = new ThreadLocal();private static final int WRITE_OPERATION = 1;private static final int MAP_COPY_OPERATION = 2;final ThreadLocal lastOperation = new ThreadLocal();
没错,他就是一个ThreadLocal,所有的一切都是围绕着这个ThreadLocal来进行的。
本篇文章从ThreadLocal的源码剖析说到他在实际工作中的使用,其实小伙伴们可以发现,很多技术的底层都是我们熟悉的东西,只不过经过了层层包装,穿上了各种各样华丽的马甲之后,我们不认识他了,但是当你一步步去深究,像洋葱一样一层一层剥开他的时候,最后,你会情不自禁的感叹一句,哦—,原来如此,soga。
好了,我是阿轩,目前也在不断的学习中,欢迎添加阿轩的微信号,一起交流,一起进步。