当前位置:
编程学堂 > 在Python中创建相关系数矩阵的六种方法
在Python中创建相关系数矩阵的六种方法
相关系数矩阵(Correlation Matrix)是数据分析的基本工具。它们使我们能够了解不同变量如何相互关联。在Python中,计算相关系数矩阵的方法有很多种。今天我们就总结一下这些方法
Pandas
Pandas 的 DataFrame 对象可以使用 corr 方法直接创建相关矩阵。由于数据科学领域的大多数人都使用 Pandas 来获取数据,因此这通常是检查数据相关性的最快、最简单的方法之一。
导入 pandas 作为 pd
将seaborn导入为sns
数据 = sns.load_dataset('mpg')
相关矩阵 = data.corr(numeric_only=True)
correlation_matrix
 导入numpy为np
从 sklearn.datasets 导入 load_iris
虹膜 = load_iris()
np.corrcoef(iris["数据"])
导入numpy为np
从 sklearn.datasets 导入 load_iris
虹膜 = load_iris()
np.corrcoef(iris["数据"])
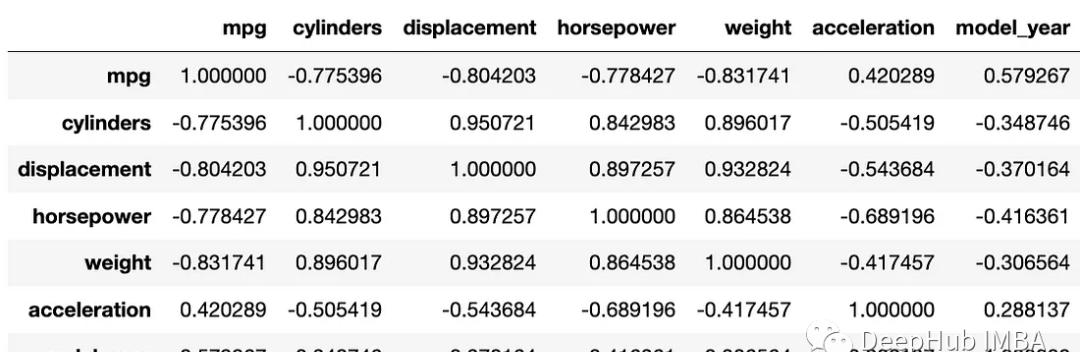 将seaborn导入为sns
数据 = sns.load_dataset('mpg')
相关矩阵 = data.corr()
sns.heatmap(data.corr(),
注释=真,cmap='coolwarm')
将seaborn导入为sns
数据 = sns.load_dataset('mpg')
相关矩阵 = data.corr()
sns.heatmap(data.corr(),
注释=真,cmap='coolwarm')
 import statsmodels.api as sm
相关矩阵 = sm.graphics.plot_corr(
数据.corr(),
xnames=data.columns.tolist())
import statsmodels.api as sm
相关矩阵 = sm.graphics.plot_corr(
数据.corr(),
xnames=data.columns.tolist())
 导入plotly.offline为pyo
pyo.init_notebook_mode(cnotallow=True)
将plotly.figure_factory导入为ff
相关矩阵 = data.corr()
图 = ff.create_annotated_heatmap(
z=correlation_matrix.values,
x=列表(correlation_matrix.columns),
y=列表(correlation_matrix.index),
colorscale='蓝色')
www.sychzs.cn()
导入plotly.offline为pyo
pyo.init_notebook_mode(cnotallow=True)
将plotly.figure_factory导入为ff
相关矩阵 = data.corr()
图 = ff.create_annotated_heatmap(
z=correlation_matrix.values,
x=列表(correlation_matrix.columns),
y=列表(correlation_matrix.index),
colorscale='蓝色')
www.sychzs.cn()
 导入matplotlib.pyplot为plt
pd.绘图.scatter_matrix(
数据,α=0.2,
图大小=(6, 6),诊断允许='历史')
www.sychzs.cn()
导入matplotlib.pyplot为plt
pd.绘图.scatter_matrix(
数据,α=0.2,
图大小=(6, 6),诊断允许='历史')
www.sychzs.cn()
 来自 scipy.stats 导入 p耳朵声
将 pandas 导入为 pd
将seaborn导入为sns
def corr_full(df, numeric_notallow=True, rows=['corr', 'p-value', 'obs']):
”“”
生成具有相关系数的相关矩阵,
p 值和观察计数。
参数:
- df:输入数据帧
- numeric_only (bool): 是否只考虑数字列
相关性。默认为 True。
- rows:确定要显示的信息。
默认值为 ['corr', 'p-value', 'obs']。
返回:
- formatted_table:与指定行的相关矩阵。
”“”
# 计算皮尔逊相关系数
corr_matrix = df.corr(
numeric_notallow=numeric_only)# 使用 scipy 的 pearsonr 计算 p 值
pvalue_matrix = df.corr(
numeric_notallow=numeric_only,
方法=lambda x, y: pearsonr(x, y)[1])
# 计算每列的非空观察计数
obs_count = df.apply(lambda x: x.notnull().sum())
# 计算每对列的观察计数
obs_matrix = pd.DataFrame(
索引=corr_matrix.columns,列=corr_matrix.columns)
对于 obs_count.index 中的 col1:
对于 obs_count.index 中的 col2:
obs_matrix.loc[col1, col2] = min(obs_count[col1], obs_count[col2])
# 创建一个多索引数据框来存储格式化的相关性
formatted_table = pd.DataFrame(
index=pd.MultiIndex.from_product([corr_matrix.columns, rows]),
列=corr_matrix.columns
)
# 将值分配给格式化表格中的适当单元格
对于 corr_matrix.columns 中的 col1:对于 corr_matrix.columns 中的 col2:
如果行中有“corr”:
格式化表.loc[
(col1, 'corr'), col2] = corr_matrix.loc[col1, col2]
如果行中有“p 值”:
# 避免使用对角线的 p 值,它们完美相关
如果 col1 != col2:
格式化表.loc[
(col1, 'p 值'), col2] = f"({pvalue_matrix.loc[col1, col2]:.4f})"
如果“obs”在行中:
格式化表.loc[
(col1, 'obs'), col2] = obs_matrix.loc[col1, col2]
返回(formatted_table.fillna('')
.style.set_properties(**{'text-align': 'center'}))
来自 scipy.stats 导入 p耳朵声
将 pandas 导入为 pd
将seaborn导入为sns
def corr_full(df, numeric_notallow=True, rows=['corr', 'p-value', 'obs']):
”“”
生成具有相关系数的相关矩阵,
p 值和观察计数。
参数:
- df:输入数据帧
- numeric_only (bool): 是否只考虑数字列
相关性。默认为 True。
- rows:确定要显示的信息。
默认值为 ['corr', 'p-value', 'obs']。
返回:
- formatted_table:与指定行的相关矩阵。
”“”
# 计算皮尔逊相关系数
corr_matrix = df.corr(
numeric_notallow=numeric_only)# 使用 scipy 的 pearsonr 计算 p 值
pvalue_matrix = df.corr(
numeric_notallow=numeric_only,
方法=lambda x, y: pearsonr(x, y)[1])
# 计算每列的非空观察计数
obs_count = df.apply(lambda x: x.notnull().sum())
# 计算每对列的观察计数
obs_matrix = pd.DataFrame(
索引=corr_matrix.columns,列=corr_matrix.columns)
对于 obs_count.index 中的 col1:
对于 obs_count.index 中的 col2:
obs_matrix.loc[col1, col2] = min(obs_count[col1], obs_count[col2])
# 创建一个多索引数据框来存储格式化的相关性
formatted_table = pd.DataFrame(
index=pd.MultiIndex.from_product([corr_matrix.columns, rows]),
列=corr_matrix.columns
)
# 将值分配给格式化表格中的适当单元格
对于 corr_matrix.columns 中的 col1:对于 corr_matrix.columns 中的 col2:
如果行中有“corr”:
格式化表.loc[
(col1, 'corr'), col2] = corr_matrix.loc[col1, col2]
如果行中有“p 值”:
# 避免使用对角线的 p 值,它们完美相关
如果 col1 != col2:
格式化表.loc[
(col1, 'p 值'), col2] = f"({pvalue_matrix.loc[col1, col2]:.4f})"
如果“obs”在行中:
格式化表.loc[
(col1, 'obs'), col2] = obs_matrix.loc[col1, col2]
返回(formatted_table.fillna('')
.style.set_properties(**{'text-align': 'center'}))
直接调用这个函数,我们返回的结果如下:
df = sns.load_dataset('mpg')
结果 = corr_full(df, rows=['corr', 'p-value'])
结果






![[系统教程]Win7原版镜像重装之后连不上网络的解决办法](/upload/images/124195428)



![[系统教程]Win10撤销更改无限重启进不去系统怎么办?](/upload/images/124198998)
![[系统教程]Win10如何关闭USB通知?Win10关闭USB通知教程](/upload/images/124198999)
![[系统教程]Win7怎么查找关机错误原因?Win7查找关机错误原因的方法分享](/upload/images/124206739)
![vs2010是否支持c 11_[CC++]VS2010对C++11标准的头文件规定的支持列表](/upload/images/35480538)











